
-
- ■産学連携
- 国際交流
- ダイバーシティ
- 情報理工学の創造的展開プロジェクト
- 受賞・表彰

東京大学 大学院情報理工学系研究科 教授
略歴
1999年 東京工業大学理学部 情報科学科卒業。2004年 東京工業大学大学院 情報理工学研究科 数理・計算科学専攻 博士課程修了、博士(理学)
IBM東京基礎研究所、東京工業大学大学院 情報理工学研究科 計算工学専攻 客員准教授、アイルランド国立大学ダブリン校 客員准教授、バルセロナスーパーコンピューティングセンター客員教授、IBM Research のアイルランド・ダブリン拠点、本部のIBM T.J. Watson Research Center(通称ワトソン研究所)及び MIT-IBM Watson AI Labを経て、2021年から東京大学大学院 情報理工学系研究科 教授(現職)。
研究分野は人工知能、特にグラフニューラルネットワーク(GNN)に関する理論構築・応用研究
研究室URL:
https://sites.google.com/view/toyolab/
グラフ構造とは、ノードとノード、そしてそれらをつなぐエッジから構成されるデータ構造のことだ。鈴村教授はグラフニューラルネットワークと呼ばれる、グラフ構造に対してニューラルネットワークを用いて解析する技術の基礎研究や、機械学習も取り入れたさまざまな応用研究を行っている。その応用先は、金融機関における不正検知やEコマースの商品推薦、都市における交通流解析、材料科学など、枚挙にいとまがない。長年海外企業を拠点に研究実績を積み上げ、2021年から東京大学で研究を始めた鈴村教授に、詳しい研究内容の他、今後日本人研究者が国内外問わず活躍していくための考察もお聞きした。
(監修:江崎浩、取材・構成:近代科学社 出版事業部)
Q. 先生の研究テーマとキャリアについて教えていただけますか
鈴村――はい。私はグラフニューラルネットワークと呼ばれるグラフ構造に対する機械学習技術の理論と応用に関する研究を進めています。詳細に入る前に、少し自己紹介をさせていただきます。2004年に博士課程を修了後、17年間IBMの基礎研究所であるIBM Researchで研究活動を行ってきました。IBM Researchの東京拠点である東京基礎研究所で研究を開始し、2013年にアイルランド・ダブリン市にあるIBM Research Dublinに移り、その後2015年にアメリカのニューヨークに移住。IBM Researchの本拠地であるIBM T.J. Watson Research Centerで研究活動を進めました。また、MITとIBM Researchとの共同研究所であるMIT-IBM Watson AI Labでも研究を進めました。アメリカでは米国の永住権を取得し、日本に戻ってくるのは大分先のつもりでいましたが、新型コロナをきっかけに日本に帰ることを決意し、2021年に東京大学に移ってきました。
Q. 研究に関しては「グラフ構造」というのがキーワードでしょうか
鈴村――グラフ構造については、ご存じない方もいらっしゃるでしょう。数学者レオンハルト・オイラーが1736年にグラフ理論を提唱しました。グラフ構造という、シンプルですが強力なデータ構造とその解析理論に関する研究です。もの・こと・人などをノード(頂点)と呼び、その関係性をエッジ(枝)と呼びます。むしろネットワーク構造と言ったほうがわかりやすいかもしれません。皆さんネットワークというと、TwitterやFacebookなどのソーシャルネットワークを思い浮かべるでしょう。世の中を見回すと、何かと何かは必ず関係性を持っています。商品の関係性を考えると、例えばiPhoneとiPhoneケースというのは補完的な関係を表していますよね。いわゆる「関係性」が存在すれば、グラフ構造で表現できます。様々なものやこと、人がこれらの関係性を持っているので、非常に強力なツールと言えます(図1)。

図1 東京大学情報基盤センターの大型ディスプレイを用いて鈴村研究室が扱う様々なグラフ構造を可視化
Q. インターネットもグラフ構造と言えますか?
鈴村――はい。インターネットのノードというのは、ウェブサイトのURLが一つ考えられます。ウェブサイト同士はリンクでつながっていますよね。それも大きなグラフ構造です。他には皆さんが使っている交通ネットワークもそうです。例えば交差点と交差点のつながり、駅と駅のつながりというのはグラフ構造です。あとは知識グラフというものがあります。知識グラフは概念と概念の関係を表した構造で、例えば「鈴村は、東京大学に勤めています」といったことを表現すると、「鈴村」「東京大学」というのが1つ1つのノードで、「勤めています」というような関係性があり、いわゆるエッジになります。概念と概念の集合体を、グラフの大きなネットワークで表す。こういう構造ができると、例えば「鈴村は、どこに勤めていますか?」ということを質問したとき、エッジをたどっていけば東京大学という勤め先が分かる訳です。
Q. 先ほどお話に出ましたソーシャルネットワークついて、何か研究をされていますか?
鈴村――はい。2012年ごろには、ソーシャルネットワークのグラフ構造に関する研究を行いました。1967年に心理学者スタンレー・ミルグラムが行った「スモールワールド実験」と呼ばれる有名な社会実験があります。その実験では、世界中の全ての人は、6ホップでつながっていくのではないかという結果が示されました。例えばアメリカ大統領につながりたいとしたら、任意の人に手紙を出していけば、6ホップでつながるということですね。このホップ数を隔たりと呼びます。
我々はデジタルの世界、特にオンライン上のソーシャルネットワークでこの隔たりがどうなっているかについて関心を持ちました。デジタル世界のネットワークは実世界よりも小さいと予想しますが、果たしてどのぐらい小さいか。そういった問いです。また言語間での隔たりの違いにも注目しました。この解析のため、Twitterの約4.7億アカウントと287億エッジという超巨大なネットワークを収集し、スーパーコンピュータを用いて隔たりの計算を行いました。
Q. どのような結果が出たのでしょうか
鈴村――Twitterネットワーク全体の隔たりは4.59でした。「スモールワールド実験」での実世界の隔たりは6ホップであったことと比べると、デジタル世界ではより小さな世界であることが定量的に示されたわけです。
また、言語間での隔たりも調べました。計算の結果、日本語圏は4.01。約4ホップつながれば日本語を話すすべての人につながるとわかりました。ところがスペイン語圏やフランス語圏は、それぞれ隔たりが4.63、4.70。日本語圏よりも隔たりが若干大きくなりました。日本語は日本でのみ話されているので、当然隔たりも小さくなります。しかし、スペイン語を話す人はスペインとメキシコにもいます。複数の国でその言語を話す人がいるので、ネットワーク上の隔たりは大きくなります。フランス語圏でも同様のことが言えます。直感とも合っているかと思います。
デジタルの世界、特にTwitterのソーシャル・ネットワーク上では、日本語圏よりもスペイン語圏、フランス語圏のネットワークの方が「隔たりが大きい」という社会学的な知見が客観的な数値として得られました。この解析を行った2012年ごろはスーパーコンピュータを用いた高速グラフアルゴリズムの開発が研究テーマの1つだったのですが、その応用としてこのような社会科学的な解析にも取り組みました(図2)。
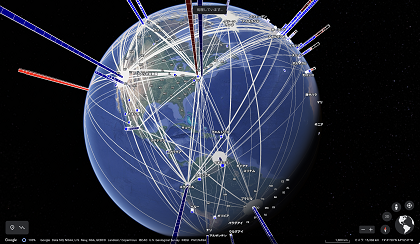
図2 Twitterネットワークが地球規模で拡がる様子を可視化
Q. データを取る技術が進歩したことも、グラフ構造の解析には重要ではないでしょうか
鈴村――世の中の現象や人間の社会活動に関するデータがデジタル化されてきたからこそ、様々な関係性が取得できるようになってきました。グラフ解析技術はこれからますます重要になっていくと考えています。グラフ構造やその解析技術を理論的に体型付けるグラフ理論は数学者オイラーによって300年以上前に提唱されましたが、まだまだ衰えることを知りません。そもそも世の中の事象と概念というのは何らか関係性を持つことがほとんどでグラフ構造として表現できるのですから、課題が尽きることはないでしょう。
Q. 昨今の様々な解析技術にはAI、つまり機械学習が活用されています。グラフ構造の解析に関してはどうでしょうか?
鈴村――従来、グラフ構造の解析技術では主に何らかのパターンを抽出するために様々なアルゴリズムが提案されました。例えば、道路交通ネットワークではある地点からある地点までの最短経路を求めるアルゴリズムです。最近、グラフの世界ではパターン抽出のみならず、データからグラフ構造のノードを分類したり、エッジの存在を予測する機械学習ベースの技術が急速に発展してきています。
例えば、ソーシャルネットワーク上で各人が好きな趣味を当てる問題があるとします。データや機械学習を用いない場合は、「各人の知り合いで最も多い趣味をその人の趣味と予測する」といった単純なルールを作って解決するでしょう。しかし当然そのルールを精緻に作ることはできません。機械学習ベースのアプローチでは、グラフのデータからこのようなルールを自動的に抽出していきます。
Q. 機械学習ベースということですが、深層学習に関連した研究はありますか
鈴村――はい、グラフニューラルネットワーク(以降、GNNと呼ぶ)という深層学習ベースの手法が盛んに研究されています。GNNでは、ニューラルネットワークを用いて、ノードの役割を分類、エッジを予測するモデルをデータから帰納的に学習します。
例えば先ほどの例を用いて考えてみましょう。先ほどは、ソーシャルネットワークの情報からルールを決めて、ある人が嗜好する趣味を予測しました。ノードの役割を分類する問題です。GNNでは、ルールを決めず、友人との関係性、友人の嗜好性、その他の属性からその影響度合いをニューラルネットワークで学習し、予測していきます。ある人の嗜好性を決めるのに、当然全く影響を与えない友人、強い影響を与えた友人がいるでしょうし、その友人は更に別の友人から影響を受けたかもしれません。そのような影響度は非常に複雑な非線形の関数で表現されますが、それをニューラルネットワークで学習するというものです。データからルールを自動的に学ぶと考えても良いと思います。
Q. なるほど。先生はいつ頃からグラフ解析の研究を始められたのでしょうか?
鈴村――2009年頃になります。当時客員准教授として東京工業大学で受け持った「離散構造とアルゴリズム」という講義でグラフ理論を教えたことがきっかけでした。ノード数が10億以上の大規模なグラフに対してクラスタ計算機やスーパーコンピュータ上で高速に動くアルゴリズムや、統一的なプログラミングモデルで並列分散アルゴリズムを記述するためのソフトウェア処理系の研究に取り組みました。Graph500というスーパーコンピュータ上でグラフアルゴリズムの速さを競う世界コンペティテョンがあるのですが、それにも挑戦し、スーパーコンピュータ京を用いて世界一位を10回達成することができました。今のスーパーコンピュータ富岳でもその当時考案したアルゴリズムが使われており、いまだに世界一位を保持しています。
その後2013年にアイルランド・ダブリンに移り、スマーターシティの研究所で交通シミュレーションの研究を行いました。しかし、グラフ解析の研究を追求したく、2015年には米国ニューヨークにあるIBM T.J. Watson Research Center (通称ワトソン研究所)に移りました。高速なグラフデータベースやグラフ解析アルゴリズムの研究を行い、また、ニューヨークのマンハッタンにある多くの金融機関と共同研究を行いました。そこではマネーロンダリング(資金洗浄)と呼ばれる犯罪の検知アルゴリズムに携わりましたが、そのような中、どのように犯罪のパターンを自動的に検知できるか考えるようになり、自然と機械学習とグラフアルゴリズムの融合に関して模索するようになりました。
Q. では銀行との共同研究で、グラフ解析と機械学習の融合に活路を見出した、と
鈴村――はい、金融機関との共同研究がきっかけで、AML(Anti-Money Laundering)、つまりマネーロンダリングの不正検知に取り組み、そこでグラフ解析と機械学習の融合の必要性を認識しました。マネーロンダリングは、犯罪等で得られたお金を金融システムの中に投入し洗浄していくという金融犯罪でして、様々な犯罪パターンがあります。日本でもマネーロンダリングは深刻ですが、アメリカではさらに深刻で、その検知を見過ごした金融機関は多額の制裁金を課せられるケースもあります。どの金融機関にとっても、AIを用いてどのようにAMLのパターンを検出できるというのが大きな課題です(図3)。

図3 イギリス金融庁で開催された不正検知に関するハッカソンで研究者たちと議論
Q. それは検知することが急務になりますね。グラフ解析と機械学習の融合についてもう少し詳しく教えてください
鈴村――大きな金融機関でのトランザクション(取引)は年間10億件ほどありますが、そこから0.01%程度のマネーロンダリングのパターンを見つけなければなりません。金融の取引は口座から口座へのお金の流れなので、口座をノード、エッジをお金の流れと捉えると、巨大なグラフ構造として表現できます。グラフ構造が大規模であるという特徴を持つと共に、時間的な発展が意味を持つという特徴を持っているといえるでしょう。このようなグラフ構造の中に潜む犯罪のパターンを見つけるというのが解くべき問題でした。
2021年に東京大学に移る直前まで3、4年ほど、このような問題に取り組みました。グラフアルゴリズムから計算されたグラフ特徴量を機械学習の特徴量として導入するアイデアや、End-to-endでグラフニューラルネットワークを用いて犯罪のパターンを検出する手法を考え、金融機関の実データを用いてその有効性を評価しました。そういった金融機関との取り組みを進める中、IBMでは製品化の話が進み、考案したグラフ構造の学習エンジンの製品化に成功し、世の中の金融機関で導入されることになりました。ニューヨークは金融都市ですから、そこでの金融機関に導入できたのは研究者として、技術者として大きな仕事だったと言えます。

Q. 金融機関での不正検知の他に取り組んでいる応用例はありますか?
鈴村――様々な領域の推薦問題やマッチングの問題にも取り組んでいます。世の中では、何らかのサービス提供者とその消費者が存在し、その両者のマッチングの前に必ず消費者にはサービスや商品の推薦があるわけです。このように日常的に行われているマッチングや推薦問題に対して、グラフニューラルネットワークを用いた新たな推薦システムの研究を進めています。また、推薦問題に取り組むにあたっては、現実のサービスに貢献するような研究を進めたいと考えており、複数の企業と共同研究を行っています。推薦問題といっても業界毎にその推薦する対象が変わってきますが、オンラインショッピング上では商品推薦、新聞社とは記事推薦、自動車会社とは目的地推薦、医療介護領域では仕事の推薦問題に取り組んでいます。より高精度で高速な推薦システム、そして全く新しい価値を提供する推薦システムを作っていきたいと思います。
Q. 様々な分野での推薦問題にグラフニューラルネットワークが活かせるのですね
鈴村――はい。皆さんがよく目にするものですと商品推薦があると思います。「この商品を購入している人はこういう商品も購入しています」というような推薦ですね。この推薦を実現する古典的なアルゴリズムに協調フィルタリングという手法があります。協調フィルタリングでは、同じような商品群を購入したユーザーを類似ユーザーと定義し、類似ユーザーが購入した商品を推薦します。この手法では、ユーザーと商品とのインタラクション(閲覧や購入)だけの関係だけを見ています。
近年はユーザーや商品の直接的な関係性も様々な情報ソースから取得できるようになってきたので、それらをエッジとして表現します。このようにモデリングすることでグラフ構造がリッチになり、グラフニューラルネットワークを用いてユーザーと商品の関連度をより精緻に計算することができます。この関連度のスコアを用いてユーザーに適切な商品を推薦できるわけです。
Q. 新たな関係性をどのようにグラフ構造に落とし込むのでしょうか
鈴村――例として、iPhoneとiPhoneケースの関係性を考えましょう。通常、iPhoneケースの概要欄には「このケースはiPhone12用です」と書かれていると思いますが、この自然言語をパースして使用します。もしくは最近は、知識グラフと呼ばれる概念と概念の関係性を構造化したデータもあるので、それらを活用することも一つの方法でしょう。説明文をパースするか、既存の知識グラフを活用して、商品同士の関係性を抽出します。ユーザー同士の関係性に関しては例えばソーシャルネットワークを用います。
商品同士の関係、ユーザー同士の関係が抽出できると、より意味のあるグラフを作ることができます。協調フィルタリングのアルゴリズムではユーザー同士の類似性、商品同士の類似性は、それぞれ共通の購入アイテム、もしくは共通の購買ユーザーを通して計算されました。間接的な類似性の計算になります。ユーザーと商品アイテムとのインタラクションの情報だけではなく、商品の説明やユーザー同士の関係を直接的に活用し、それをグラフに埋め込むことで、より精度の高い推薦システムを構築することができます。
Q. 先生は日本の大学に移られましたが、海外企業との違いはありますか
鈴村――アカデミアに移ってきて改めて思うのは、問題設定の自由度が高い環境だということですね。私は最初IBM東京基礎研究所で研究を始めたのですが、IBM Research全体の戦略があって、東京は何をする、アイルランドは何をするという風にある程度方針が決まっていました。各拠点の担当範囲が戦略上決まっていて、研究者に解くべき問題の方向性が決められている。大学では研究に関してはこれをやってはいけないなどとは言われない。そこはアカデミアの良さであると再認識しています。理論の研究もしつつ、応用に関しては企業と取り組んでもいい。個人商店であると同僚の先生が仰っていましたが、まさにその通りだと思います。もしその研究が上手くいかなかったとしても、それは自分のリスクですから。そういった意味で、チャレンジがしやすい環境だと言えます。
Q. 企業と比較してアカデミアの長所は何だとお考えですか?
鈴村――繰り返しになりますがアカデミアは企業と違って、どのような問題を選び・解くかに自由度があります。その自由度が最大の長所だと思います。短期的なリターン、企業だと売上でしょうが、それを求められることはない。ただ、そういう高い自由度がある中、問題の選び方は慎重かつ大胆に選ばないといけません。情報、特にソフトウェアの分野は実用化までのタイムスパンが短いので、そこまで長期的な研究テーマを追求できません。しかし、短すぎても、大きく世界を変えるような研究テーマは設定できない。
問題設定を考えるときには、アカデミアの制約も考える必要があります。チームサイズ、使える計算資源、アクセスできるデータセットなど。それらの制約の中で、自ら達成したい時間軸を見据えつつ、その中で研究的に最もインパクトのあるテーマを探す必要があります。どの問題を解くのかは慎重に選ぶ必要があります。間違った問題選びをしてしまうと、あっという間に時間を費やしてしまいます。繰り返し自分の仮説や問題設定を見直し、必要であれば問題を再考しなおせる柔軟さを持つことが、大きなインパクトを出す上で意識すべき非常に重要な点なのかと思います。
Q. ではアカデミアと企業が共同で研究することの意義はいかがでしょう
鈴村――実際に提供するサービスの観点から研究テーマを企業側と議論でき、かつそれに紐付いたデータを提供してもらうことができるので、実証が可能な有意義なテーマ設定ができる点です。手法に関しては、アカデミアの方が企業よりも相対的に長いタイムスパンで考えられるので、企業にとっては模倣されないようなユニークな手法をアカデミアと開発できることもメリットです。アカデミア、もしくは企業の片方で実現できるものではなく、まさに双方が協働するからこそ実現できるのでしょう。
企業との共同研究の場合は、先ほどお話したようにアカデミアだけに閉じた研究テーマではないので、企業の利益やコストを考える必要があります。先ほどのアカデミアでの自由度の話と少し矛盾するかもしれませんが、そのような制約があるからこそ、より面白い研究テーマも生まれてくるかと思います。
Q. アカデミアでは学生の指導も行われます。学生に伝えたいことはありますか?
鈴村――博士課程と海外への挑戦に関しては修士1年の時点で真剣に考えて欲しいと思います。学部の時点では、自分が博士課程に進学すべきかどうか見極めるには経験がないので判断が難しいでしょう。修士1年がベストでしょうか。もし修士2年を過ぎており、就職する事が決まっている人であっても、いつか社会人ドクターとして博士号を取りに大学に戻って来るということも考えても良いのではないでしょうか。
まず博士号を持つことの意味をお話しします。アメリカや欧州に住んで、博士号取得者の立場が全く違うということを強く実感してきました。欧米の多くの企業が博士号を要求し、博士号を持っていることが有利に働く場面を多く見てきました。技術者・研究者として働く上での免許証のようなものでしょうか。
人によっては、キャリアチェンジし、コンサルタントなど「ものづくり」以外の道に行く人もいます。そういう場合でも、博士号を保持している人はしっかりとした技術的バックグラウンドを持っている人材として有利に働いたケースを多く見てきました。欧米では博士号はこのような位置づけにあります。
今後の日本経済では、日本の外を見ないと仕事として先細りしてしまうのは言うまでもありません。そんな時代の中で、研究者の道に進む人だけが特別に取る学位ではなく、欧米の標準に合わせて、より多くの人に博士号取得を目指してほしいと思います。
Q. では、博士課程に進んで得られることにどういうことが挙げられるでしょうか?
鈴村――まず博士課程を終えるには、当然、国際的に認められる科学的な成果を出すことが必須であり、技術力が身につくことは言うまでもありません。技術力以外に得られることをお話しします。
学部の4年生、そして大学院の修士課程に進むと、研究に必要な一連のプロセスを経験します。研究領域の最新動向を把握するために関連論文を調べる、研究テーマを決める、周囲の研究者を説得する、研究の進捗を管理する、設計・実装・評価を行う、そして最後に結果を論文としてまとめる、聴衆の前で説明する、といった一連のプロセスを経験することになります。
そのプロセスを学部4年生、修士課程で経験するわけですが、本格的に自らそのプロセスを経験するのは博士課程に行ってからこそです。これが博士課程で得られる最も貴重なことでしょう。企業に入ってもなかなかできません。企業での仕事に置き換えると、市場調査、プロジェクトのテーマ立案、社内の説得、プロジェクト組成、プロジェクト管理、設計・開発・評価、そして広報と営業になるでしょうか。このような一連のプロセスを一人で全部経験することは企業ではなかなか難しいでしょう。規模こそ違いますが、大学院での一連の研究のプロセスは、企業でのこれらの活動に似ています。
社会に早く出てこういう一連の仕事のプロセスを学びたいと言う人が多くいますが、私はそこに少し疑問があります。博士課程でこのような一連のプロセスを経験した人こそが企業に入ってきても強い。博士課程を終えた後は、当然ものづくりを続けて頂きたいですが、研究職だけに拘らず多様な職種に進んでもいいと思います。博士課程で得られる自立自走できる力こそが、その後のキャリアにとって大きな武器になります。
Q. 博士号への挑戦以外にお伝えしたいことはありますか?
鈴村――博士号への挑戦と同時に、海外にも挑戦してほしいです。博士課程の時に海外で過ごすことによって、日本の小さなコミュニティだけではなく、様々な国籍の人が交じるコミュニティの中で、研究の一連のプロセスを経験することになるので、社会人になっても、世界だ、グローバルだと臆することなく、自然に活躍できるようになります。博士課程に行くことに加え、その中で半年や1年でもいいので海外で研究する機会を作って欲しいと思います。
Q. 最後に学生へのコメントをお願いします
鈴村――本日は、私のこれまでの研究、そして現在進めている研究テーマの一部をお話しさせて頂きましたが、より詳しく知りたい方は私の研究室のホームページや論文などを読んでいただければ幸いです(図4)。博士課程に進学する学生が極端に少なくなっていますが、敢えてこれを機会にお話しさせていただきました。是非一度博士号や海外に挑戦することを考えてもらえればと思います。私も相談にのりますので、遠慮なくメール等で連絡してください。
(取材日:2022年12月16日)

図4 鈴村研究室のメンバーとの食事会
1 数学者レオンハルト・オイラー : 18世紀の数学者・天文学者。数学者としての膨大な業績と、後世の数学界に与えた影響力から、ガウスと並ぶ数学界の二大巨人の一人と言われる。グラフ理論の始まりは、1736年にオイラーが最初の定理となるネットワーク・アプローチを用いて「ケーニヒスベルクの橋の問題」を解いたことだと言われる。
2 心理学者スタンレー・ミルグラム : 米国の心理学者で、20世紀の最も重要な心理学者の一人と言われる。イェール大学在職中に、スモール・ワールド現象(六次の隔たりの元になった概念)などについての社会実験を行ったことで知られている。
3 協調フィルタリング : ある対象者が商品をチェックまたは購入したデータと、対象者以外がチェックまたは購入したデータの両方を用い、その購入パターンから人同士の類似性などを解析し、対象者個人の行動履歴を関連づけることでパーソナライズされた商品を提示することができる手法。
Copyright © 2019 Graduate School of Information Science and Technology, The University of Tokyo