
-
- ■産学連携
- 国際交流
- ダイバーシティ
- 情報理工学の創造的展開プロジェクト
- 受賞・表彰

profile
鈴木 大慈 (すずき たいじ)
東京大学情報理工学系研究科数理情報学専攻 准教授
略歴
2009年 東京大学大学院情報理工学系研究科数理情報学専攻、博士課程修了。東京大学大学院情報理工学系研究科数理情報学専攻准教授(現職)。機械学習、統計的学習理論、数理統計学、データ解析についてその理論から応用を研究している。
ホームページ:http://ibis.t.u-tokyo.ac.jp/suzuki/
機械学習は今やAIの要として世間での認知度も非常に高まっている。中でも深層学習は、大規模データの取得とコンピュータ処理能力の向上によって高レベルな認識精度を持つようになった。画像認識や音声翻訳、果ては自動運転技術と、社会に多大な影響を与える技術が作られ続けている。一方で深層学習は「どうしてその答えが出てきたかわからない」という学習過程のブラックボックス化が問題視され、産業界での利用も限定されている。鈴木大慈准教授はこの問題に対し数学・数理の力を使って真正面から立ち向かっている。今回、鈴木准教授には深層学習の現状と進化の可能性、そしてAIが我々の社会とどう関わっていくかをお聞きした。
(監修:江崎浩、取材・構成:近代科学社編集チーム)
Q.先生の研究について簡単にお伺いできますか?
鈴木――基本的には機械学習の理論的な研究に携わっています。統計的な学習方法と、具体的な計算方法の二つですね。学習には計算が必要になりますが、その計算を速くさせるためにアルゴリズムの研究をする必要があります。機械学習の分野では今まで色々とやってきましたが、最近は特に深層学習の研究を進めています。
Q.深層学習の数理的理論の研究ということでしょうか?
鈴木――はい。深層学習というのは、実はなぜうまく学習できているのか正直よくわかっていない部分があります。ですので、原理をしっかり解明して、ブラックボックスではなくホワイトボックス化したい。共同研究させていただく企業からもそうした案件を頂くことがあって、興味を持っている人が多いと感じています。あとは、深層学習を超えたいという野望があります。
Q.もう少し深層学習についてお聞きします。内部でどう計算しているかわからないと言われていますが、それはどのくらいでしょう? 本当に何もわからない?
鈴木――本当になにもわからないほどブラックボックスというわけではありません。そこに理論がなくても、直感で解釈できるという部分は結構あります。ただ、よくよく考えてみると理論はよくわからないよね、という所がたくさんあります。
Q.直感というのは、こうなるだろうと思う結果がちゃんと導き出される、みたいな?
鈴木――そうですね。エンジニアリング的な、こういう風にやれば良いんじゃないかというある種の理論に近い考えがあって、それに基づいてネットワークを構成するとうまくいくという事があります。ですので、よく誇張して言われるような錬金術じみた話ではありませんが、挙動が予測できないとか、どういう学習ができるのか、といった点で未知の部分がありますね。
Q.それはまだ学問として確立されていないという面もあるように思います。
鈴木――そうですね、それをやろうとしているのが私の研究と言っても過言ではないかもしれません。直感に頼っている部分をより数学的にしっかり形式化して、学問にさせていくことを目指しています。
Q.では、深層学習は今どれくらい理論化が進んでいるのでしょう?
鈴木――深層学習の理論は三つパートがあります。一つが関数近似能力。データが無限にある場合、どういう問題が解けますか、という話です。二つ目はデータが無限ではなく有限の場合、どこまで学習できるのかという汎化誤差の話があります。
Q.汎化とはつまり、どれだけ精度が出せるかという問題でしょうか?
鈴木――その通りです。三つ目が学習の最適化。学習を始めて、どれだけ良い解が得られるかというのが、実はよくわかっていない。機械学習ではカーネル法などがよく使われてきましたが、それでは達成できない学習が深層学習ではできるという事が、徐々にわかってきています。
Q.深層学習の性能についてもう少し詳しく教えてください。
鈴木――深層学習はすごく柔軟で、様々なタスクに応じた適切な特徴抽出の能力に長けています。ある問題に対して重要な特徴量、情報というのを具体的に取り出す能力と言い換えられるでしょうか。今までの機械学習だと、はじめにあらゆる情報を吸い取れるように特徴量を用意しておかないといけないのですよね。適応的ではないので、これだとターゲットを絞りきれない。その分無駄があって、学習が遅くなります(図1)。

Q.今までの機械学習はお膳立てをしてあげなければいけなかった?
鈴木――そうです。深層学習だと、対象に適応的にフィットできる能力が強いので、目の前の問題にスペシフィックな状態に自分を変えていける、ということです(図2)。ただその状態でなんでもできるわけではない。

Q.むしろ、それしかできないような?
鈴木――はい。深層学習は、そういう風に自分をフィットさせることがすごく得意なんです。新しい応用ができるかというとまだギャップがありますが、今まで何もわかっていなかったところが、だいぶわかってきているという段階まで来ています。
Q.深層学習の発展には数学の発展もあったと思いますが、いかがでしょう?
鈴木――どちらかというとコンピュータ技術の発展が影響していますね。画像認識の精度はどんどん上がってきていますし。で、数学はそれに追い付いてないのが現状です。最近やっと少しずつ深層学習の動きがわかってきたんですよ。先ほど言った、適応能力が強いこととか。
Q.なるほど。ちなみに深層学習を超えたいというお話をされていましたが、この先ももっと進化するのでしょうか?
鈴木――まだまだ進化します。ただし、データにないものは学習が難しいというのが深層学習でも大きな問題でして。我々のように自分たちで論理を組み立てる、 演繹して考えるというのが非常に不得意です。
Q.現段階ではまだ力仕事の部分というか、人の調整が必要だと?
鈴木――そう思いますね。やはり精度を上げるためにはデータが必要でしょうし。先ほど説明した、深層学習は適応能力が高いという点をもっと伸ばす、より使いこなす学習方法を考えていかなければいけません。
Q.では、現段階の深層学習でできること、やるべきことはなんでしょう?
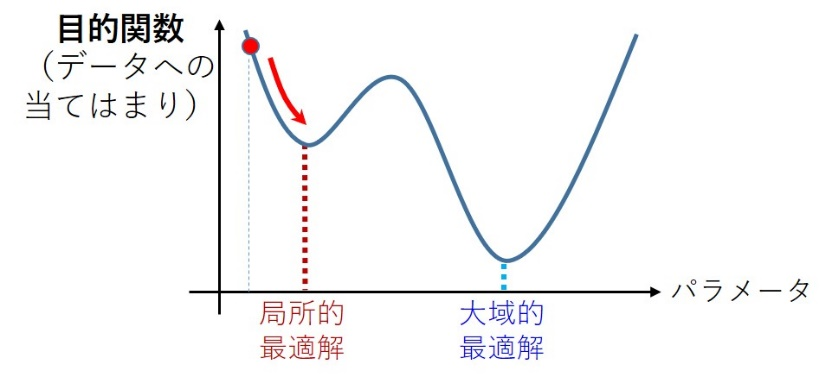
鈴木――できることはまだまだありますが、色々と問題もあります。たとえば最適化が収束しているのかわからない、とか。というのも、目的関数をグラフに書くと局所的な最適解がたくさん出てくるわけです。なので、本当に一番良い解にいっているかわからない。試行錯誤してどうにか上手くいく、という状況なんですね。学習が上手くいっているかどうかハッキリわかるような学習方法を作れないか考えているところです。
Q.それは深層学習の次の技術に繋がるのでしょうか?
鈴木――そうですね。たとえば無限次元の最適化みたいに捉えることによって、局所的な最適解ではなく、ちゃんと正しい最適解にいることが保証されるような学習方法を作るとします。そうすると、どこで学習を止めれば良いか、どういう正則化をすれば良いかがわかり、パラメータチューニングが非常にクリアになると考えられます(図3)。今の深層学習では、学習をずっと続けていると急に精度が上がったぞ、ということが起こるのです。
Q.なぜそうなるのかは、研究者としては当然解明したいところですね。
鈴木――そうなんですよ。解明して、それを解決する。新しい方法を作り、それを実現するアルゴリズムを提案していきたいと思っています。
Q.先生のお話を聞いていますと、物理学的なところもあるように感じます。
鈴木――はい、ありますね。非常に物理学的です。深層学習そのものが物理学の対象になっているということも関係していますが。
Q.深層学習自体が解明の対象ということですか?
鈴木――はい。相対性理論や量子力学が物理学の領域で発展したように、深層学習に対しても理論があり、証明できるはずです。そこからの話ですが、相対性理論を基にしてGPSが作られたり、量子力学で電子の振る舞いを解いて半導体が生まれるという事例がありましたから、深層学習でも機械学習でも、理論がわかればその先に行ける可能性が開くわけです。
Q.機械学習や深層学習は、広義でいうAI技術に属すると考えられます。AI自身の進化、強い人工知能の実現はどうお考えですか?
鈴木――実現にはまだまだ遠いでしょうね。ただ、機械ができること自体は人間を超えていることもたくさんある。たとえば画像認識で画像を処理できる量に関しては1秒間に数十枚、並列化すれば数万枚も処理できますし、1枚の画像から全体の情報を抽出できるという機能は人間と比べものにならない。つまり各タスクに特化しているわけですが、全体的になんでもできるような強い人工知能とは決して言えないわけです(図4)。それを達成する鍵となるのがさっき言った、演繹の能力でしょう。
Q.自分で物事を考える、推測するという能力ですね。
鈴木――そう、論理を積み重ねられるということです。さきほど仰られたようにお膳立てした問題、たとえば画像認識や翻訳といった世界ではものすごく強い存在になりますが、その世界からは出られない。
Q.ブレイクスルーが必要ということですね。具体的にはどういう方向性が考えられますか?
鈴木――それがわかれば有名になれるわけですけど(笑)、誰もわかっていないのが現状ですね。有力だと考えているのは因果推論ですが。
Q.因果推論とは?
鈴木――たとえば人がボールを投げることで説明しますと、こういう動作をしたからボールはこう動く、という原因と結果の関係を表すものです。それを人が教えないで、機械が独自に論理を組み立てていくことが必要と考えられています。この因果推論の機能は金融の世界でも求められています。機械が因果推論できるようになると、エクセルのデータを与えただけでなんらかの関係性を見出すかもしれない。人間はエクセルの表を眺めただけではなにもわからないので、そこは機械の強みが活かされるでしょう。
Q.現行の深層学習はより多くのデータを持っているほうが有利とも聞きます。そこにコンピューティングパワーが合わされば一人勝ちのようにも言われますが、先生はどうお考えですか?
鈴木――ある意味で真だと思っています。ただ少数サンプルで学習したいと考える人は多く居て、そのための 転移学習という技術も現れています。ですので、より多くのデータを持っている企業の方々は転移学習のベースとなる特徴抽出の部分を頑張っていただいて、それを世の中に配布してもらうのがいいかもしれませんね。
Q.少ないリソースかつ頭を使って勝負ができる環境が必要ということでしょうか?
鈴木――そうですし、そういう環境を作っていきたいですね。誰でも勉強すればわかる、勝負ができるというか。そうでなければGoogleの一人勝ちになってしまう。
Q.そのGoogleを含むGAFAや中国は機械学習の分野で進んでいるという印象を受けます。日本の情勢はどうでしょう?
鈴木――正直言って遅れていますね。各個人での研究では健闘していますが、明らかに数で負けています。アメリカの10分の1か、それ以下かなという感じです。
Q.それは研究者の数が?
鈴木――研究者の数です。例えばNeurIPS(Neural Information Processing Systems)やICML(International Conference on Machine Learning)などの機械学習のトップカンファレンスがありますが、そこでアクセプトされた論文はアメリカ、イギリス、中国の方が上ですね。対する日本は数で圧倒されています。
Q.日本の対策としては研究者を増やしていかなければいけない?
鈴木――増やしてほしいですね。そのためには研究費の問題もありますが、やはりポストの問題を解決しなければいけない。海外ではDepartment of machine learning(機械学習学科)、Department of statistics(統計学科)がありますが、日本にはどちらもほとんどないです。日本中の研究者を集めてやっと海外の有名大学の一学科を満たすみたいな。誇張している部分もありますが、それくらいの差があると考えています。
Q.地道に人材を増やしていくしかない、と?
鈴木――機械学習や人工知能の学科だけ増やしても角が立つので、なかなか難しいとは思いますけどね。まずはそういう差というか規模感を持ち、裾野を広げていかなければいけない。たとえばスカイツリーが634メートルですけど、スカイツリーの周辺の建造物よりは高いですが富士山には全然届かない。今の日本の事業でも一つひとつのプロジェクトを頑張ってスカイツリーは作れるけど、富士山にはならないということが多いですから。

Q.先生の立場としてはどういうアプローチをお考えですか?
鈴木――数理的な基礎力がある人がもっと増えてほしいですし、こちらから輩出していかないといけないとは考えています。あと研究者としては、研究室でこういうことをやっているとしっかり発信していくことですね。ビジョンを共有してもらう。そうすれば日本の機械学習、人工知能研究が盛り上がっていくと思いますし。私にできるのは、研究で語っていくことかなと。
Q.もう少し大きい話になりますが、情報技術によって社会はどう変化していくとお考えですか?
鈴木――やっぱりAIが鍵だと思います。人間がやらなくてもいい仕事をAIなりロボットが肩代わりする社会ですね。たとえば創薬。医療の現場はコロナウイルスで大変な状況だと推察しますが、50年後だったらAIがワクチンを作るための網羅的探索を一挙に担っているかもしれない。人間の場合はマンパワー頼りになってしまいますが、AIの活躍で改善すると思います。人にとって大変な作業をAIがサポートする世界になるといいですね。
Q.大学と企業の違い、あるいは関係性についてどうお考えでしょうか?
鈴木――個人的な考えですが、たとえばGoogleと物量で勝負するのはやはり厳しい。しかし、我々のような研究領域だと比較的個人でも戦える。なので、そのような個人で戦える領域に進むという戦略があります。
Q.逆に言えば、それは企業ではできない?
鈴木――そうかもしれません。機械学習は企業との距離が近い分野だと思いますが、企業でもできてしまうことを大学でやるのはあまりよくない。私達の研究は大学独自の強みが生かせる分野かなと思っています。
Q.では、企業とのコラボレーションの経験はどうでしょう?
鈴木――既に関わった分野の話ですと、小規模かつ局地的な天気予報に深層学習を使うという共同研究はさせていただきました。あとは製造業で、工場のラインの中の各センサーをどう統合するか、という研究もあります。金融の分野でコラボレーションをさせていただくこともありますね。
Q.金融の世界で起こることを方程式で表そう、というお話になるのでしょうか?
鈴木――単純にもっと内部のデータ解析が必要で、機械学習を使おうという発想ですね。元々金融分野は数学者や物理学者を集めて解析を行っていたのですが、最近は機械学習も取り入れようという機運があるので、私がコラボさせて頂いているわけです。で、金融の世界もより データドリブンな動きが目立つようになりました。深層学習のようにフレキシブルなモデルを使って、予測をするというフェーズに移ってきています。
Q.では、企業とのコラボレーションで重要視しているのはたとえば、多くのデータを使用させてくれること、あるいは数学数理のしっかりしたバックグラウンドを持つ人材と研究を進めること、などでしょうか?
鈴木――後者の方を重視しています。もう少し言えば、我々の基礎研究を、より現実に吸い上げてくれるようなマインドを持っている方とは共同研究しやすい。今までの事例でもそういうマインドを持っていらっしゃる方が多かった。企業の利益に繋がるようなことは企業側で進めていただけると、お互いwin-winな形になりますよね。
Q.企業とのコラボレーション、共同研究で得られるものは?
鈴木――たとえば我々の研究は理論中心なので、コンピュータビジョンの応用に応じたノウハウというのが少なかったのですが、共同研究を通して情報共有できたことが良かったですね。あとは先ほど説明した転移学習を実際に共同研究し始めたのですが、なかなか上手くいかなくて。そのときどういう問題があって難しいのか、という肌感覚のような共有があるのも利点ではないでしょうか。
Q.逆に企業側が先生に期待されていることもあるかと思います。たとえば企業側には知られていない技術を提案してほしい、というような。
鈴木――確かにそこは期待されていると感じますね。まだよくわからない、有名ではないが良い技術というものを探されているというのは、あると思います。あとは各案件ごとにアイデアを提供したりといったこともあります。ここで行き詰っているんだけど、という相談には、数理的観点から解いてみる。ある意味でノウハウというか、お互いの情報共有がメリットになるのでしょう。
Q.先生の研究室で、学生さんはどういった研究をされているのでしょう?
鈴木――たとえば、深層学習の適応能力を理論的に証明したというものがあります。無限次元でのスパース推定というのを、実は深層学習がやっていると。そういう観点で見ると、従来の機械学習より精度が良くなっていることが理論的に証明できる、という研究を学生さんに担当してもらいました。結果として、その研究は統計の学会で最優秀報告賞をいただくことができました。
Q.そうした研究テーマはどういう風に決められるのでしょう?
鈴木――研究のやり方としては、こちらが幾つかテーマを用意します。比較的広めにテーマを持ってきて、学生さんにそれをまず読んでもらって、興味があるところにフォーカスする。最初はそんな感じで、どんどんとスペシフィックに突き詰めますね。
Q.議論を通じてインタラクションされていく?
鈴木――そうですね。学生とあーでもないこーでもないと議論して、概念を共有していく。逆に話すことで自分もわかっていなかったことが認識できたりもします。
Q.研究室の議論は非常に実りがあるのですね。
鈴木――それは間違いないと思いますね。機械学習は理論寄りの分野ですので、より応用寄りの他分野に比べるとかなりオープンだということもあります。基礎的なバックグラウンドを持った学生さんだと、数学的な概念が良く伝わるので議論がしやすいですね。研究室にはインターンで海外から来てくれる人も居るのですが、そういう学生さんと他の研究室のノウハウを共有できるのもありがたいです。
Q.まずは研究室に来て話をしたほうがいい?
鈴木――私は研究室に来てもらわないとだめですよって言いますね。 Twitterでの議論もありますが、やはり限度があります。独学でやって難しいものが、研究室に入ると急にできるということもある。研究室の学生さんでも相互に影響を及ぼしているでしょうし。
Q.そうすると、先生の研究室では数学的なバックグラウンドを身につけつつ、研究のお話で伺ったような直感も磨いていくという感じでしょうか?
鈴木――そうですね。今は機械学習や深層学習というツールが揃っているので、誰でも使えるしある意味では誰が何をやっているかもだいたい見当が付く。ですので、まずは数式でちゃんと証明して、原理を一回しっかりと理解する。厳密にこなすことによって直感も養われると思います。要はツールに使われるのではなく、ツールを使う側になろうということです。
Q.なるほど。では、先生の研究室の学生達には、将来どのようなことを期待されていますか?
鈴木――今は人工知能ブームですが、私はこの後にAIの氷河期が来ると踏んでいます。機械学習、つまりAIのコモディティ化が進んで誰でも使えるという話になった後ですね。
Q.AIは冬の時代を繰り返していますが、また来るのでしょうか?
鈴木――はい。それがこの2~30年くらいに一度来て、そこから先程説明したような因果推論ができる深層学習が出てくると予想しています。学生の方々にはいわゆる強いAIを使って、世の中をどう良くしていくか、ということを今から考えながら動いて欲しい。就職活動にしても、どういう会社に行って何をするかを見据えた人生設計、あるいは研究テーマを考えてほしいですね。
Q.学生のうちからAIでなにをしていくか、その展望を持つべきと?
鈴木――そうですね。社会的な問題だと、今から2~30年後は少子高齢化がより進んでいるでしょうから、地方行政の問題が深刻になっているかもしれません。現在は東京一極集中がどんどん進んでいますが、そうすると地方は過疎化が進む。そういう時代にAIはもっと活躍できると思っています。介護だったり、子育てだったり、製造業でも人間の代わりに働いてくれる人工知能があれば、地方もより活性化するのではないでしょうか。むしろ東京にいる必要はないという世界が来れば、もっと住みやすくなるはずです。
Q.さきほどの情報技術によって変化する社会のお話にも繋がるわけですね。AIについては、仕事を奪われてしまうという文脈で語られたりしますが、むしろ必須になってくると?
鈴木――はい。無くなる仕事はたくさん出てくるでしょうが、学生さん達が見据えるのはこれから生まれるであろう仕事のことです。特に東大の学生さんが目指すべきは、Googleのような巨大企業に使われない人材になることでしょう。機械学習やAIの話をすると、AIは人の仕事を奪うから研究は止めるべきという論調を耳にしたりしますが、AIの研究を止めればGoogleにお金を捧げるだけの存在になってしまうだけです。AI対人間ではなく、人間対人間の世界ということを意識すべきです。
Q.Googleと渡り合うためにAIの勉強をすべきだ、と?
鈴木――まぁそうですね。結局、技術力で逆転できる世界だと思いますから。この分野ではビジネスチャンスもたくさんあるはずです。学生さんとしては、今までの企業像に縛られないような自由な発想で、自分の人生を進んで頂ければ。逆に企業側も、そういう自由な研究というのをより推進されてもいいのではないかと思います。
Q.AI、つまり機械学習の勉強をすべきとのことですが、どういう学生さんがその分野の研究に向いているとお考えですか?
鈴木――もちろん数学ができるというのは当然ですが、一方で柔軟性もほしいですね。データサイエンティストはコミュニケーション力がないとダメとも言われたりするのですが、柔軟性があって、色んなツールと数学的な理論を対象に合わせて選択できることが大切です。理論に固執しちゃうのもよくないんですよ。こうあるべきだ、この手法を使うべきみたいな感じではなく、問題を定式化、モデリングして的確な解決方法を与えられるような柔軟性です。そのためには知識と技術が必須です。
Q.先生の研究室では、その柔軟性を持つという方針があるのでしょうか?
鈴木――そこはちょっとずれますね。先程の話は企業の開発に近いもので、私の研究室でうまく教育しているかというと、必ずしもそうではないです。ただ、研究を進めていく中で必要な素養というのは自然と身につくものだと考えています。間接的にはそういう能力が育っているんじゃないかと。
Q.では、先生の教育に関するポリシーとは?
鈴木――問題を定式化して、議論しながら洗い出していくことでしょうか。学生さんは何がわかっていなくて、どういう問題を抱えているかということを明確化していく。最終的にはそれを一緒に解いて論文という形にしていく、という方法を実践しています。
Q.先生の研究室に入るメリットについても教えてください。
鈴木――数理情報学専攻は数学を使って問題を解こうという専攻なんですけど、その中で比較的ウチの研究室は、機械学習という分野の性質から潰しがきくというか、様々なものに触れる機会があります。理論の面でも色々な数学のトピックに触れられるし、応用という意味でもデータ解析、コンピュータビジョン、金融、自然言語処理と間口が広い。機械学習自体が総合格闘技っぽい面を持っています。そういうのを面白いと思う人は、ぜひ来て欲しいですね。
Q.では、先生の研究室を出られた卒業生はどのような進路に行かれるのでしょう?
鈴木――やっぱり機械学習を使うところが多いですね。金融もですが製造系のメーカとか。製造系企業の中でもデータ解析や機械学習部門ができ始めていますから。あとは博士に行く。海外の大学に博士課程を取りに行った人もいます。
Q.なるほど。では最後に、情報以外の分野で注目されている方はいらっしゃいますか?
鈴木――東京大学物理工学専攻の沙川貴大先生ですね。 マクスウェルの悪魔という思考実験がありまして、粒子一つひとつの動きを観測すると「熱力学第二法則」に一見反する現象が起きてしまうのですが、実は、情報処理に必要なエネルギーを考慮に入れれば矛盾は起きないという研究を発表されました。個人的には興味がありますね。一度お話してみたいです。
(取材日:2020年3月24日)
1 カーネル法:パターン認識において使われる手法の一つ。 判別などのアルゴリズムに組み合わせて利用する。カーネル法の名前はカーネル関数を使うことに由来する。
2 演繹:与えられた命題から、論理的形式に頼って推論を重ね結論を導き出すこと。対義語は帰納:個々の具体的な事例から一般に通用するような原理・法則などを導き出すこと。
3 強い人工知能:人工知能が人間の知能に迫る、広範囲の人間の仕事をこなす、幅広い知識と何らかの自意識を持つことを示した造語。対して弱い人工知能は、人間の全認知能力を必要としない程度の問題解決や推論を行うソフトウェアの実装を指す。
4 転移学習:ある領域で機械学習が学習したこと(学習済みモデル)を別の領域に役立たせ、効率的に学習させる方法。学習時間の短縮、スモールデータで高精度を出せるという利点がある。
5 データドリブン(Data Driven):経験や勘ではなく、様々な種類の情報とアルゴリムによって分析された結果をもとに、ビジネスの意識決定や課題解決などを行う業務プロセス。
6 Twitter:Twitter, Inc.のソーシャル・ネットワーキング・サービス。「ツイート」と呼ばれる半角280文字(日本語は全角140文字)以内のメッセージや画像、動画、URLを投稿できる。
7 マクスウェルの悪魔:物理学者ジェームズ・クラーク・マクスウェルが提唱した思考実験、ないしその実験で想定される架空の働く存在。分子の動きを観察できる架空の悪魔を想定することで、熱力学第二法則で禁じられたエントロピーの減少が可能であるとした。
Copyright © 2019 Graduate School of Information Science and Technology, The University of Tokyo