
-
- ■産学連携
- 国際交流
- ダイバーシティ
- 情報理工学の創造的展開プロジェクト
- 受賞・表彰

profile
東京大学 大学院情報理工学系研究科(数理情報学) 教授
略歴
2000年 東京大学 大学院理学系研究科 情報科学専攻 博士課程 修了、博士(理学)。
東北大学大学院 情報科学研究科、九州大学大学院システム情報科学研究所、国立情報学研究所を経て、2014年から東京大学 大学院情報理工学系研究科(数理情報学)教授(現職)。
専門分野はアルゴリズムとデータ構造。新型コロナウイルスのDNA配列決定にも関わり、2021年度「科学技術分野の文部科学大臣表彰」において、「大規模メタゲノム解析の基盤技術の研究」が科学技術賞を受賞。
著書に『簡潔データ構造(アルゴリズム・サイエンスシリーズ8 数理技法編)』(共立出版)がある。
ホームページ:
https://www.i.u-tokyo.ac.jp/edu/course/mi/index.shtml
あらゆる分野で大量のデータ処理が必要とされるビッグデータ時代。深層学習(ディープラーニング)を用いた人工知能技術も一般化し始め、ますますビッグデータの扱いが重要課題となっている。データを圧縮したままの状態で、高速な問い合わせが可能となる「簡潔データ構造」の実用化に向けた研究を果敢に進める定兼邦彦教授に、詳しいアルゴリズムやビッグデータ時代を見据えた応用、先の新型コロナウイルスのRNA配列決定に貢献したアセンブリなど幅広くお話しいただいた。「やってみたら上手くいったではなく、なぜそれが上手くいくのかを考えてやることが大事」、そう繰り返す定兼教授の思いとは
(監修:江崎浩、取材・構成:近代科学社 DF編集部)
Q.先生の研究内容について簡単に教えてください
定兼——私の主な研究テーマは「簡潔データ構造」です。簡潔データ構造がどういうものかと言うと、Wikipediaによると「情報理論的下界に近い領域量だけを使いつつ、他の圧縮形式とは異なり、効率的に質問を受け付けることができるデータ構造」と書かれていますが…この説明では難しいですよね。噛み砕いて言うと、ビッグデータは大きいのでなるべく圧縮して持っておきたいのですが、通常の圧縮方式だと圧縮したままでは使えません。圧縮しても、結局使う時には一度元に戻さなければいけない。なので別の圧縮方式を使い、圧縮したままの状態でいろいろな問い合わせなどができるという、そういったデータや、それに関係するデータ構造の研究をやっています。
Q.圧縮したまま使えるとは、どういうイメージなのでしょう
定兼——「文字列検索」で例えますと、まず文字列が100GBあったとします。そこから何かを検索をしようとすると、データ構造を構築しなければいけませんが、100GBというのは結構な量です。本には「索引」がありますが、基本的に重要な単語しか載っていない。もし索引に全ての単語を載せるとしたらサイズがすごく大きくなって、その100GBのテキストに対して接尾辞配列などの索引のサイズが680GBとなり、合計で780GBにもなってしまいます。そのままでは普通の計算機だと処理できません。それを上手に圧縮することで、780GBが22GBほどに圧縮されて、しかも圧縮したままの状態で検索したり、必要な部分だけを復元できたり、そういった操作が可能になるという研究をしています。

図1 文字列 abacac$ の接尾辞配列 SA
Q.データを圧縮するだけでなく、そのまま使う、ということに重きを置いていると
定兼——そうですね。データを圧縮したまま処理をするとお話ししましたが、最近ではそれを拡張してセキュリティの話まで進めています。秘匿計算といって、データを圧縮したまま、かつ暗号化したまま処理するというアルゴリズムやデータ構造についての研究です。量子計算のアルゴリズムなども少しやっていますが、秘匿計算も量子計算も「data oblivious」、つまり条件分岐が無い。アルゴリズムの動作がデータに依存しないという意味で似ているなと感じていますね。
Q.様々な用途に使えそうです
定兼——はい、道路データに関する研究もあります。例えば、ここに関東地方の三浦半島周辺の地図がありますが、道路の座標データというのも結構な量なんです。これはそこまで小さくなってはいませんが、14GBなのが2GBぐらいに小さくなっていて、なおかつ小さいままで普通に使えます。あとは、新型コロナウイルスの研究にも関係しています。
Q.もう少し詳しく教えてください
定兼——DNA配列のアセンブリという処理に関して、データ構造を開発しました。先ほどの「文字列検索」の拡張みたいなものです。「アセンブリ」というのはDNAやRNAの配列を決定する処理ですが、DNAなどは結構長い文字列で表されています。現在は、長いままだと読み取れないので、短く切ってから機械で読み取っていて、それをつなぎ合わせるという処理をしています。その時にすごくメモリが必要で、例えばヒトのDNAを全部つなぎ合わせる処理をしようと思うと、通常だと300GBものメモリが必要になります。それが簡潔データ構造を使うことで100分の1ぐらいになる。どのようなデータ構造かは非常に専門的な話になってしまうので割愛しますが、新型コロナウイルスの配列の決定の時に我々のソフトウェアが使われまして、それは広く社会の役に立てたかなと思っています。
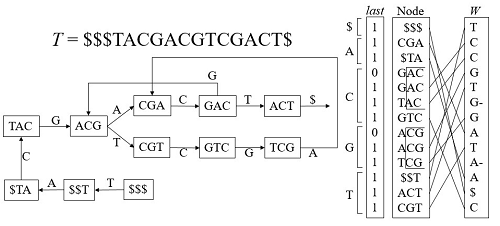
図2 DNAのアセンブリ処理で使われるデータ構造
Q. 通常のアルゴリズム研究・データ構造の研究と先生の研究とでは、どのような違いがあるのでしょう?
定兼——通常、データ構造の研究で計算量の評価の時には、「定数倍は無視する」という感じでやるのですが、私の研究室では「簡潔」と言っている通り、小さくないぎりぎりのところまで圧縮してということなので、下界にぴったり一致するようなデータ構造を作るというところが違うのかなと考えています。
Q. 先生が研究されている「情報理論的下界」とも関連している?
定兼——「下界」というのは数学用語で、専門外の方にはなじみのない言葉かもしれません。情報論理的下界というのは、k種類のもののうちの1つを表す際に何ビット必要かという値で、kのlogを取った値となります。例えば「n=3」として、「1、2、3」という集合の部分集合は何個あるかということを考えると、全部列挙すると2の3乗で8個あるのですが、それを表現するには3ビット必要ということになります。2ビットだと4種類しか表現できないですが、3ビットだと8種類表現できるので、下界は3ビットということになり、3ビットで表現するということが目標になります。もう少し一般的な例を挙げると、木構造があります。「n=4」で4ノードの順序木というのは5つあり、一般的にnで表現すると4のn乗くらいの値になります。これはlogを取ると2nビットぐらい、つまりnノードの木というのを表現するには、2nビット必要ということなんです。だから目標は木を2nビットで表現して、かつ木の親を求めるとか、子どもを求めるとか、そういう操作を高速に実現するためにはどうすべきか、ということを常に考えています。
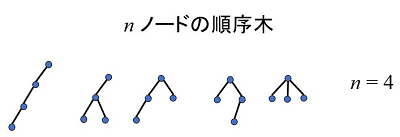
図3 順序木の列挙。4ノードの順序木は5個存在する。
Q. 「簡潔」というのが圧縮のキーなのですね
定兼——そうです。もう少し説明すると、通常、線形サイズのデータ構造というとデータ数に比例する領域を使うという意味になりますが、実は皆さんが普通に使っている線形は実は線形ではありません。データ数をnとした時に、よく「オーダーn、nに比例する」と言うのですが、本当は「n log nに比例している」ということです。配列があったとして、ポインターのサイズというのは実は定数ではなく「log n」に比例するものなので、本当はnが増えると線形よりももっと大きく増えていっています。それを線形と言っているわけです。だから、それは本当の意味では線形ではないので、「オーダーn」と言ったら、「オーダーnビット」で行うにはどうするのがいいかということを考えていかなければいけない。
Q. なるほど。では、簡潔データ構造の研究を始めるきっかけは何だったのでしょうか?
定兼——2000年にR.Grossi氏とJ.S.Vitter氏が発表した論文(Compressed Suffix arrays and Suffix Trees with Applications to Text Indexing and String Matching)がすごく面白いなと思って、そこから始めたという感じです。先ほどのDNAの検索でもありましたけど、文字列の検索をする時に接尾辞配列を持っておいて検索するのですが、このサイズが大きいという問題があり、それを圧縮するという論文でした。
Q. そこから「圧縮したまま使える」という現在の研究につながったのですね
定兼——その通りです。私も前から接尾辞配列の研究はやっていて、接尾辞配列を圧縮して保存することを試していました。彼らの論文ではそれを圧縮したまま検索できるということを発明していて、私はそれを改良するような研究を行いました。
Q. いわゆる「ビッグデータ時代」では、情報量が爆発的に増えています。圧縮したまま使える、という研究の利便性は大きいのでは
定兼——DNAのゲノム情報に関しては、昔は圧縮しないデータ構造が使われていましたが、今はほとんど全てが圧縮されたデータ構造を使っているはずです。他には道路の渋滞などの交通情報もビッグデータとして扱われるようになるでしょう。これまではハードディスクの上にデータを置いてきましたが、データ量が多いと読み込みが遅くなりますし、特に検索はすごく遅くなっていました。そういう時にデータ圧縮をしておくと、ある程度のデータがメモリに入るので高速検索が可能になると思います。
Q. 一方で、PCマシンは昔に比べメモリ自体も強化され、処理の速さも上がっています
定兼——確かに計算機のメモリも昔と比べたら何百倍に上がっているかもしれませんが、その分データ量ももっと増えているということです。だから結局、いくら圧縮ができたとしてもエントロピーより小さくはならないので、どうしてもディスク上に置く必要はある。なるべくメモリ内で処理できる量を増やすというのが大切です。
Q. 「ビッグデータ時代」では圧縮だけでなく秘匿、つまり中身が見えないことも重要です
定兼——そうですね。私は既に秘匿計算を研究していますが、秘匿計算というのは「データがどこにアクセスしたか」という情報すら秘匿したいんです。そのためデータ構造の研究とはちょっと相性が悪いという意見もあります。データ構造の研究は、上手く作れると高速に検索できるということなのですが、そうするとデータのどこにアクセスをしているのかが判明してしまう。だから秘匿計算では、通常は全部のデータにアクセスしてしまうんです。そうすることで、どこへアクセスしたかが分からなくなる。
Q. その点が量子計算と近い?
定兼——量子計算がなぜ速いかを一言で説明すると、並列処理をしているからなんですね。全部のデータが重ね合わせの状態で表現されているので、全部のデータで同じような計算を同時にできるから速くなる。だから、全部のデータを一気に扱うという点で両者は似ていると思います。あとは先程も言いましたが条件分岐がないこと。秘匿計算では条件分岐があるとデータの情報が漏れてしまいます。量子計算は特定のデータに対して何かするということはなく、全部に対して同じことをするので。
Q. 先生は量子コンピュータや、そのアルゴリズムについての研究もされていますか?
定兼——一応やってはいます。まだビッグデータ処理ができるぐらいのデータを扱える計算機はないので、机上の空論ではありますが。でも私が思っていたよりも早く量子計算機が実用化されそうだなと思っています。まだビット数が非常に少ないという課題はありますが、10年、20年後には使えるようになるかもしれません。
Q. 深層学習やAI研究が世界中で加熱しています。先生の研究と関連はありますか
定兼——実はデータ圧縮と機械学習は非常に近いところがあります。データ圧縮というのはデータのモデルを予測し、こういうデータが出現しやすいことが分かると、そのような、データに対する符号を短くすることで圧縮が実現できるという仕組みです。それに対し機械学習の方は、こういうデータが出現しやすいというのを学習するのが目的なので、ほぼ同じようなことをやっていると言えます。そういう意味で、機械学習の方もこれから本格的に取り組むかもしれません。
Q. MPCを用いた差分プライバシーは大変大きな計算機クラスターを準備する必要がありますが、そのような実用的な計算方法について、圧縮技術の展望はいかがでしょう
定兼——共同研究者と進めている内容は、機械学習とも関係しますが、学習するとその分データ量を減らすことができます。そうやってデータ量を減らしておけば解析も高速化できるのではないかという観点で研究を進めています。情報量を落とさないまま計算しよう、データ解析しようという時に方法は2通りあると考えていて、1つはGPUなどを多く使って強引に計算すること。もう1つはアルゴリズムの改良を待って高速化するということですね。私は後者のアプローチです。
Q. データ量を減らすことは問題はないのでしょうか
定兼——情報が落ちてしまうという心配をされるかもしれませんが、私は基本的に「可逆」な圧縮をしています。先ほど機械学習では学習データを圧縮することで減らしていると言いました。一見すると「非可逆」な圧縮をしていますが、圧縮というよりは、データ量をサンプリングで減らしてやっているような感じで、基本的に全ての情報はあるということです。そのため圧縮方式によっては、こういう解析は高速でできるけど、他の解析には時間かかる、ということはあるかもしれません。
Q. それは問題とデータによって一番良い方法を模索すべきということでしょうか
定兼——そういうことです。深層学習のモデルをどう学習するかという話と、その学習をいかにデータ構造などで効率化するかという話は別だとは思いますが、モデルに関してもやってみたら上手くいったというよりは、なぜそれが上手くいくのかというのを考えるべきだと思います。
Q.先生の研究テーマの選び方について聞かせてください
定兼——機械学習などの研究では、新しくこういうことができるようになった、という具体的な目標があると思いますが、私はどちらかと言うといかにデータを圧縮するか、いかに高速化させるか、に興味があります。応用先はたくさんあると思いますが、今は数理構造的な部分の研究を重視しています。現実の中で問題が発見された時に、それをどうやって数学的なアプローチで整理して解いていくか、がテーマとして重要です。
Q. たとえば企業の方から「こんな難しい問題があるけど解けない」といったチャレンジが来たとして、先生が面白いと思えば研究テーマになりますか?
定兼——ぜひお声がけいただきたいです。私は特定のこの問題を絶対解きたいというよりは、この問題にはこれが使えるなとか、いかにして解くかとか、そうした試行錯誤と技術の応用方法が面白いと考えていますので。
Q. ご自身は数理的な方法で問題を解き、企業側が社会に還元していく、そんなコラボレーションの形が見えてきます
定兼——そうですね。先ほどのDNAのアセンブリの話ですと、香港大学の人たちに作っていただいたソフトウエアは、いろいろな企業や研究機関で使われています。これまではスーパーコンピュータを使ったり、高価な計算機を使ったりして、お金で解決するようなことが行われていました。でも実はアルゴリズムやデータ構造を改良すると、そんなことをしなくてもビッグデータ処理ができるようになる。企業とタッグを組んで、ある意味で“エコ”な社会貢献をできるんじゃないかなと思います。

図4 香港大学で共同研究をしていた頃の様子。左からTak-Wah Lam先生、Wing-Kai Hon先生、定兼先生、Siu-Ming Yiu先生。
Q. 将来的には汎用的なPCでも、ビッグデータの解析ができるようになる?
定兼——様々なデータに対してそういうことが可能になるといいなと考えています。GPUを並列で使って力ずくで解決するというのも有効な方法ですが、GPUを何台も並べてやらなくても、1つだけでできるようにデータ構造を作るのが私の役割かなと思いますね。
Q.大学の研究者だからこそできること、やれることについてはどうお考えですか
定兼——繰り返しになりますが、やってみたら上手くいったというよりは、ちゃんとなぜそれが上手くいくのかというのを考えることが重要です。「理論的にこの問題はこうやってやるとちゃんと解ける」ということを、保証することが研究者の役割なのかなと思います。
Q. 数理の面から現実の問題を解くには、やはり数学という学問の探究が必須でしょうか
定兼——私が使っている数学は、普通の人が思う数学よりはだいぶ簡単なものじゃないでしょうか。数学は数学だけれども、計算時間など「正しく解が求められるか」という観点が問題になってくるので。でも、たとえばプログラミングなんかだと、ちゃんと数学を勉強しないで書くと、実行にどれだけ時間がかかるかわからないということはあるでしょうね。
Q.数学を知っていると、有利に動くことができると
定兼——そうです。「絶対にこれぐらいの時間で終わる」ということを保証することが、研究者として重要だと考えています。こういう入力に対しては正しく解が求まらないとか、プログラムが止まらないとか、そういう勘どころでも数学的な素養が必要です。
Q. 最近だと、Pythonのライブラリを使えば深く理解せず手軽にできてしまいます
定兼——そうですね。プログラムが上手くいけばいいのですが、もしかしたらそれを下手に組み合わせるとすごく無駄なことをやっているかもしれなない。何となく書けば動くと思って書いている人も多いかもしれませんが、より大きなデータを扱うようになると、ボトルネックのところが出てきてしまうはずです。アルゴリズムなどをわかった上で書かないと、結局大規模化はできないといった壁に当たりかねません。そこで「じゃあGPUを増やそうか」といった方向に行くのではなくて、ちゃんとアルゴリズムを考えて、これは無駄なことをしているからこうすべきだということを考えた方がいいでしょう。
Q. データ処理に関してGPUは魅力的ですが、逆にパフォーマンスが悪くなる可能性もあると
定兼——はい。そういう意味では、数学とコンピューターサイエンスの知識は持っていた方がいいです。機械学習は数学が必要だし、データをどう扱うかということだとコンピューターサイエンスの知識が必要になります。特に複雑な問題、大きな問題を解こうとする時には、そういったバックグラウンドがないと良くないことが起こる可能性があります。
Q. 研究室の指導方針はありますか?
定兼——うちは学生の指導に関して、「指導しなくても学生さんが自分で考えてやってくれる」という状態が理想的だと考えています。教えてもらって何かをやるのではなくて、自分で考えて研究してほしいので。別に放置するわけではないのですが、言われるままにやっているだけだと頭に入らなくて、自分でいろいろ考えているうちにふと腑に落ちるというか、悟りの境地が開くのではないかな(笑)。
Q.先生が具体的にされていることはありますか?
定兼——基本的には「この論文、読んでみて」という感じです。学生さんが何かに興味を持ったようであれば、それを勉強したり展開できたりするような論文を手渡します。上からテーマを与えられて、という方法とは違いますね。逆に言えば、私の研究室に入れば「自分のやりたいことができる」という点がメリットと言えるかもしれません。

※インタビュー中は感染症対策のため、マスク着用としております。
Q.先生の研究室に入る学生さんとしては、どういう方が向いていますか?
定兼——私の興味がアルゴリズムやデータ構造なので、そういうものに興味がある人だったら一緒にできると思います。でもそうじゃない人でも、だったら一緒に勉強しましょうと言います。
Q. プログラミングスキルなど、必要なスキルはありますか?
定兼——プログラミングはできた方がいいですが、別にプログラムが書けなくても論文を書くことはできるので、プログラミングのスキルはあってもなくてもどっちでもいいです。あった方が、実際にいろいろプログラムを書いてみてということができるので、有利だとは思いますが。むしろ「論理学」に重きを置いたほうがいいでしょう。話が通じる、相手に伝えられるということは論理学で、アルゴリズムも結局は論理です。
Q. 先生の研究室に行くと、論理学的な思考が学べるわけですね
定兼——うちの研究室だけでなく大学は全てそうだと思いますが、重要なことなので。別にスーパープログラマーがたくさんいても仕方ないですから。論理的に考えられることが一番大事です。アルゴリズムを簡単なものからでも基礎教養として取り入れていくべきなのかなと、最近では感じていますね。
(取材日:2022年8月1日)
1 接尾辞配列:文字列の接尾辞(開始位置を異にし、終端位置を元の文字列と同じくする部分文字列)の文字列中の開始位置を要素とする配列を、接尾辞に関して辞書順に並べ替えて得られる配列のこと。文字列探索、全文検索などに利用される他、単語の出現回数を高速に求めたり、データ圧縮に使えたり、様々な応用例が提案されている。
2 条件分岐:プログラム中で、ある条件が満たされているかどうかによって次に実行するプログラム上の位置を変化させること。また、そのような分岐を行うコード。
3 アセンブリ:集合、組み立て、組立部品などの意味を持つ英単語「assembly」のこと。ゲノムアセンブリは,DNAやRNA配列を切断した断片からもとの配列を復元することを指す。
4 木構造:データ構造の1つで、一つの要素(ノード)が複数の子要素を持ち、子要素が複数の孫要素を持ちというふうに、階層が深くなるほど枝分かれしていく構造のこと。ツリー構造ともいう。
5 線形:比例を意味する。アルゴリズムの線形時間とは、実行にかかる時間が入力サイズに比例するということ。
6 MPC:マルチパーティ計算のこと。複数のサーバー間で通信を行いながら、ある計算を分担して行うという仕組み。
7 差分プライバシー:個人データが識別されないようにしながら、大規模なデータセットから学習できるようにするアプローチ方法。
8 GPU:「Graphics Processing Unit」の略語。GPUは、コアと呼ばれる同時に計算を行うパーツの数がCPUより圧倒的に多い。CPUの場合、多くても数十コアに対し、GPUは数千コアにもなるため、大量の処理を同時に実行することが可能となっている。
9 Python:「パイソン」はいま最も人気のプログラミング言語。シンプルながら汎用性が高いので多くのエンジニアから支持され、人工知能を始めとしたさまざまな分野で使われている。
Copyright © 2019 Graduate School of Information Science and Technology, The University of Tokyo