
-
- ■産学連携
- 国際交流
- ダイバーシティ
- 情報理工学の創造的展開プロジェクト
- 受賞・表彰
 音楽産業に新風を吹き込みそうなシナリオがある。あなたの好きなジャンルの音楽を10曲ほどリストアップし入力すると、曲のイメージなどからあなた好みの曲を、あまり知られていない曲や新曲の中から選び出す、『音楽検索』サービスが日本でも始まるだろう。音楽を検索できるようにするには、音楽信号自体を記号データに分解しないといけない。それを支えるのが、音を分離・加工する信号処理や、音楽を言語と同じように情報として扱う情報処理技術だ。中学時代に音に魅せられて以来、音の研究に染まった嵯峨山教授が、これらの技術を駆使してどのような音の新世界を拓こうとしているのか―。
音楽産業に新風を吹き込みそうなシナリオがある。あなたの好きなジャンルの音楽を10曲ほどリストアップし入力すると、曲のイメージなどからあなた好みの曲を、あまり知られていない曲や新曲の中から選び出す、『音楽検索』サービスが日本でも始まるだろう。音楽を検索できるようにするには、音楽信号自体を記号データに分解しないといけない。それを支えるのが、音を分離・加工する信号処理や、音楽を言語と同じように情報として扱う情報処理技術だ。中学時代に音に魅せられて以来、音の研究に染まった嵯峨山教授が、これらの技術を駆使してどのような音の新世界を拓こうとしているのか―。
研究室ではミーティングの最中だった。いったん中断してインタビュー。大きなスクリーンに映し出された研究内容を見ると、「音楽」「音響」「音声」の文字がまぶしく並ぶ。中心は、音を音として扱う信号処理と、音を言語として扱う音楽情報処理だ。
音楽信号処理の基本となるのは、多重音の分離・加工。バイオリン、フルート、パーカッションの3つの楽器音が鳴った多重音(和音)があるとしよう。この音のうち、バイオリンの音を強調して聴きたいというリクエストがきたら、どうするか。まず、音の強弱を操作できるように、3つの楽器の音を分離し数値化する。あとで足し合わせて和音にするときにバイオリンの強度を強く、他の音を弱めるように混合すると、希望通りの音を聴くことができる。「理屈はそのとおりですが、技術的にはとてもむずかしい。それを実現するために私たちは独自の方法を何種類も開発しました」。たとえば、3つの楽器音の基本周波数と、この周波数の倍音構造に注目し、重なり合った3つの楽器音の周波数をすべて“連結した音”として捉えた。そこに統計的推定の学習アルゴリズムを持ち込み、繰り返し計算することによって、通常では見つけることができない目的の音を、重なり合った音の中から発見し、分離する。データを足し合わせることで望みの音をつくり出せるのだ。
| 「ピアノ演奏原音」 Nocturne-AudioTrack.wav |
ショパン作曲ノクターン第2番のピアノ演奏の原音 | |
| 「管楽器」 ConvertedMIDI-Nocturne78.wav |
調波時間構造化クラスタリング(HTC)法によって分解し、管楽器系の音で再合成したもの | |
| 「弦楽器」 ConvertedMIDI-Nocturne40.wav |
同じく、弦楽器系の音で再合成したもの |
 |
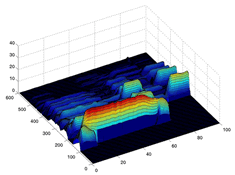 |
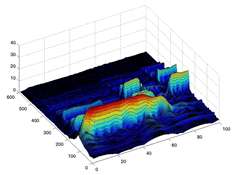
| ギター曲"For Two"の音響信号のスペクトログラム3次元表示(一部) | 調波時間構造化クラスタリングによって得た左図の混合ガウス関数モデル |
| ※画面をクリックすると、拡大画像をご覧になれます | |
名演奏家と呼ばれる音楽家は、即興で感動的なピアノ曲やジャズを弾くことがある。即興だから楽譜がない。いままでは耳コピーといって、何度も耳で聴いて覚えるしかなかったが、即興で弾いたものを楽譜として書き取る自動採譜研究も加速している。楽譜になっている曲なら、著名な演奏家が弾いたものと楽譜を当てはめると、どの部分を細工して強弱を付けたかがわかる。演奏家の独特の弾きまわしの中からルールを抽出することによって、感動を与える弾き方のノウハウさえ知ることができる。データ化されているからこそ可能なのだ。
音楽情報処理では、従来のコンピューター作曲ではなく、日本語歌詞から歌唱曲を自動作曲する研究に拍車をかけている。「歌詞は何でもいい。小説『我輩は猫である』をすべて歌にしたら、歌の長さはギネスブックものでしょうね」と教授の顔から笑みがこぼれるが、実はまじめなのだ。作詞はできるが、作曲ができない人は多い。恋人の前で口に出して言えないことも、歌にしたら伝えられるし、効果は抜群だろう。小学校の学級児童に先生が「キミたちの詞に曲をつけてあげる。みんなで聴こうよ」と言えば、子どもたちとの会話が盛り上がること間違いなしだ。
入力は歌詞、出力は伴奏つきの歌唱信号、つまり、歌声が合成音で出てくる仕掛けだ。そのために、漢字かな混じり文章からなる歌詞の読みのアクセントにマッチしたメロディーを、和声学のルールにもとづいて動的計画法(ダイナミック・プログラミング)でつくり出し、和音や伴奏などを決めていく。与えられたメロディーに和音をどのように付けていくかということも、文法理論で解くことに確かな手応えを得ている。音大で教えるような和声学を取り入れる一方、数学の最適経路設計問題を解くように、数理的な問題に還元して自動作曲に挑んでいる。こうしたアプローチが嵯峨山流オリジナルだ。
| 「与えられた歌詞(天気予報から)」 ♪金曜日の昼間は天気が回復し、太陽がチラッと顔を出します。 自動作曲結果例の伴奏つき合成歌唱音声 weather_log-rhyC-harA-accG-JUMP_mix.wav |
 嵯峨山教授が音の世界に引き込まれたのは、中学生のときに触れた英語の発音記号。綴りではわからない発音を記述する方法に興味を覚えた。映画「マイ・フェア・レディ」の音声学者、ヒギンズ教授に憧れる一方で、受験勉強の合間にピアノと和声学を独習。合唱では全国優勝の経験もある。大学院で音響信号処理を修め、NTTの研究所で音声分析、音声合成、音声認識を追求し、ATRに出向中は自動翻訳電話の開発に携わった。そして、2000年4月、東大情報理工システム情報学専攻の教授に就き、音楽信号処理・情報処理を研究テーマの中心に据えた。研究室における人材育成について問うと「呼吸するかのように基礎理論を身に付け、透明な箱を見るかのように現象の本質を見通し、珠玉の工芸品をつくるかのように理論を組み立て、熟練工のように鮮やかなシステムを構築する…」という回答がきた。こうした表現ひとつ取っても、音楽のリズム感を彷彿とさせる。
嵯峨山教授が音の世界に引き込まれたのは、中学生のときに触れた英語の発音記号。綴りではわからない発音を記述する方法に興味を覚えた。映画「マイ・フェア・レディ」の音声学者、ヒギンズ教授に憧れる一方で、受験勉強の合間にピアノと和声学を独習。合唱では全国優勝の経験もある。大学院で音響信号処理を修め、NTTの研究所で音声分析、音声合成、音声認識を追求し、ATRに出向中は自動翻訳電話の開発に携わった。そして、2000年4月、東大情報理工システム情報学専攻の教授に就き、音楽信号処理・情報処理を研究テーマの中心に据えた。研究室における人材育成について問うと「呼吸するかのように基礎理論を身に付け、透明な箱を見るかのように現象の本質を見通し、珠玉の工芸品をつくるかのように理論を組み立て、熟練工のように鮮やかなシステムを構築する…」という回答がきた。こうした表現ひとつ取っても、音楽のリズム感を彷彿とさせる。
昨年暮れ、日本語と英語の音声を自動翻訳するNTTドコモの携帯電話が登場した。長い間の夢だった外国語と日本語の自動翻訳の先駆けとなるもので、そこには教授のNTTとATR時代の基礎研究が生きている。目標に掲げている次の研究は「音楽モデル、自動採譜、さらには人間性を持つエージェントとしてのロボットに音声技術を付与すること」など。それぞれの高精度化が狙いだ。音符どおりでなくても歌えるのは、音楽モデルが存在するためとし、まだ手を付けられていないこの研究に先手を打つ。また、楽譜データとしてコンピューターに取り込むことができれば、あとの加工は思いのまま。そこから音楽の検索はもとより、音楽、音声の新しい世界が広がる。「フーガの自動作曲って、どうかなと思っているんです」。チェスが人工知能の大きなターゲットになったように、フーガの作曲も挑戦的テーマ。制約が多いからやりがいがあるとしながらも、「計算可能な問題に仕立て上げられるかどうかがカギですがね」と笑った。
Copyright © 2019 Graduate School of Information Science and Technology, The University of Tokyo