
-
- ■産学連携
- 国際交流
- ダイバーシティ
- 情報理工学の創造的展開プロジェクト
- 受賞・表彰
大量のWeb文書から対訳テキストを高速で抽出する手法を、新領域創成科学研究科修士課程の斎藤大さん、近山隆教授、情報理工学系研究科の田浦健次朗准教授らが見いだした。大量のテキストの中から指標となるテキストを選び、これと比較して似ている単語を持つテキストをブロックごとにまとめ、その後、個別に対訳があるかどうかを判定する仕組み。すべてのテキストを1対1で比較すると膨大な計算時間がかかるが、数分の1の時間に高速化できる。さらに、トピック分類に用いる文書生成モデルのLDA(Latent Dirichlet Allocation)を使い、対訳判定上、特に重要とみられる単語がどのくらい存在しているかを見ることによって計算時間を減らせることも示した。2段階で絞り込むこの手法は、Web上の膨大な文書から巨大コーパスを構築したり、特定の情報を抽出するのに役立つ。
対訳テキストは、複数の言語で記述された意味内容が同じテキストのペアで、いわば、翻訳の形になっているものを指す。対訳テキストを収集し、利用可能の形式になった対訳コーパスはあるが、政府公式文書やソフトウェアマニュアルの対訳などに限られている。Web上の大量テキストから対訳ページを自動収集して巨大なコーパスを構築できると、研究情報の収集など広範な利用が進むと期待されている。
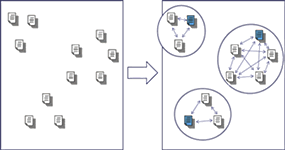 |
| 図1 効率的な対訳発見手法の原理 最初にテキスト群を似た単語を多く含むテキストごとにグルーピングをし、そのグループ内でのみ本格的な比較を行う |
斎藤さんらは、対訳コーパスを対象にし、2段階に分けて対訳判定の高速化を試みた。第一段階として、和英、英和といった電子辞書(対訳辞書)によって、類似の意味を持つ単語をまとめ、その単語を用いて指標となるテキストと比較することでブロックごとに集約した。たとえば、MovieとFilmはどちらも「映画」と訳されるので、似通った単語を持つテキストをブロックごとにまとめ、このブロック内だけで対訳判定を行うことにした(図1)。Web上にある全ページのあらゆるペアに対して、単語単位ですべてにわたって対訳判定を行うのは、計算時間とコストがかかりすぎるネックがあるが、ムダな対訳判定を減らして計算コストを削減できることを示した。次いで、LDAによる次元削減によって単語を絞り込み、判定速度と精度を高める工夫をしたのがポイントだ。
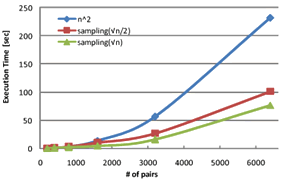 |
| 図2 グルーピングによる高速化の効果 横軸が対象とするテキストの数、縦軸が抽出にかかった時間。最初から全対全比較を行う(青線)のに比べ、グルーピングを行う(赤、 緑)ことで実行時間が削減される |
実験はLinuxマシンを使い、データとしてWebコーパスで提供されている日英対訳ページ6400ペアを用いた。対訳判定は、ペア数を200、400、800、1600、3200、6400と増やして行った。6400ペアの全対全比較には230秒かかったが、ブロックごとにまとめることで実行時間が3分の1から4分の1程度短くなった(図2)。また、6400ペアに対し、トピック数を指定してLDAをかけ、各トピックに登場する割合の高い単語を集め、テキストからこの単語のみを取り上げて対訳があるかどうかを見た。この結果、対訳判定回数が約4分の1削減でき、計算量を減らせることがわかった(図3)。誤った対訳ブロックに組み入れられる割合(誤分類率)も、LDAをかけない前の状態と差がないことも確認している。
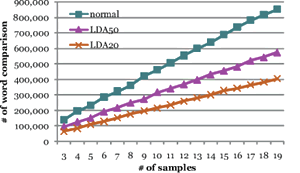 |
| 図3 LDAを用いた単語数削減による高速化の効果 横軸がグルーピングを行う際のグループ数、縦軸が対訳テキスト抽出を行うのに必要だった単語の比較数(実行時間がだいたいこれに比例する)。LDAを用いた単語数削減を行わない場合(緑)に比べ、LDAを用いて重要な単語のみを処理すること(紫、茶色)で必要な単語の比較数が削減される |
対訳テキストは、多言語自然言語処理の分野できわめて有用な資源だが、現状では、計算コストの問題から十分な量・種類の対訳テキストを入手するのはむずかしい。今回の手法を用いると、計算量の問題で収集できなかった対訳テキストを収集できる可能性が出てきたが、斎藤さんは「対訳コーパスからではなく、実際にWeb上から大量の対訳テキストを取得できるように工夫したい」と話している。
Copyright © 2019 Graduate School of Information Science and Technology, The University of Tokyo