English
入進学希望の方へ
在学生へ
学外の方へ
内部者向け
概要
研究科長挨拶
沿革
目標
運営体制
研究科データ
(教員数・学生数(在籍者数)・入学者数・修了者数)
資料・パンフレット
アクセス・学内地図
お問い合わせ
組織
■専攻
コンピュータ科学
数理情報学
システム情報学
電子情報学
知能機械情報学
創造情報学
■附属センター
ソーシャルICT研究センター
情報理工学国際センター
(ICIST)
情報理工学教育研究センター(CERIST)
■関連連携研究機構
次世代知能科学研究センター
(略称AIセンター)
数理・情報教育研究センター
(略称MIセンター)
バーチャルリアリティ教育研究センター
(略称VRセンター)
情報セキュリティ教育研究センター
(略称SIセンター)
■関連学部
工学部
理学部
教員紹介
研究科教員一覧(50音別)
研究科教員一覧(所属別)
研究科教員一覧(キーワード別)
フォーカス(教員紹介記事)
全学教員一覧(50音別)
教育
履修・学籍・諸手続案内
研究科時間割
東京大学授業カタログ
■教育プログラム等
データサイエンティスト養成講座(領域知識創成教育研究プログラム)(DSS)
知的情報処理英語プログラム
実データで学ぶ人工知能講座(AIデータフロンティアコース)
enPiT
ソーシャルICTグローバル・クリエイティブリーダー育成プログラム(GCL)
国際交流
工学・情報理工学図書館
研究
■産学連携
R2P/IST
社会連携講座
寄付講座
国際交流
受賞・表彰
設備
フォーカス(教員紹介記事)
ニュース
ニュース
受賞・表彰
採用情報
プレスリリース
イベント・各種募集案内
アクセスマップ・学内地図
寄付をお考えの方へ
お問い合わせ
サイトマップ
工学・情報理工学図書館
メディアの方へ
教員検索
アクセスマップ・学内地図
寄付をお考えの方へ
お問い合わせ
サイトマップ
工学・情報理工学図書館
メディアの方へ
English
入進学希望の方へ
研究科案内
出願手続き
修士・博士課程
研究生
大学院科目履修生
各専攻・教員の紹介
教育・学生生活
学生支援制度
国際交流室 (Office of International Relations)
在学生へ
履修情報
履修・学籍・諸手続案内
研究科時間割
東京大学学務システム(UTAS)
東京大学授業カタログ
学生・院生ポータルサイト
学生支援制度
教育・学生生活
科学研究ガイドライン
情報倫理ガイドライン
緊急連絡ページ
工学・情報理工学図書館
学内相談施設
学外の方へ
高校生の方
修了生の方
企業の方
産学連携
寄付をお考えの方へ
一般の方
イベント・各種募集案内
大学案内
寄付をお考えの方へ
採用情報
内部者向け
UTokyo Portal
学内NWから別ウィンドウで開く
学外NWから別ウィンドウで開く
情報ポータルサイト
ISTクラウド
研究倫理審査
科学研究ガイドライン
情報倫理ガイドライン
広報
緊急連絡ページ
工学・情報理工学図書館
サイト内
教員
概要
研究科長挨拶
沿革
目標
運営体制
研究科データ
(教員数・学生数(在籍者数)・入学者数・修了者数)
資料・パンフレット
アクセス・学内地図
お問い合わせ
組織
専攻
コンピュータ科学
数理情報学
システム情報学
電子情報学
知能機械情報学
創造情報学
附属センター
ソーシャルICT研究センター
情報理工学国際センター
(ICIST)
情報理工学教育研究センター(CERIST)
関連連携研究機構
次世代知能科学研究センター
(略称AIセンター)
数理・情報教育研究センター
(略称MIセンター)
バーチャルリアリティ教育研究センター
(略称VRセンター)
情報セキュリティ教育研究センター
(略称SIセンター)
関連学部
工学部
理学部
教員紹介
研究科教員一覧(50音別)
研究科教員一覧(所属別)
研究科教員一覧(キーワード別)
フォーカス(教員紹介記事)
全学教員一覧(50音別)
教育
履修・学籍・諸手続案内
研究科時間割
東京大学授業カタログ
教育プログラム等
データサイエンティスト養成講座(領域知識創成教育研究プログラム)(DSS)
知的情報処理英語プログラム
実データで学ぶ人工知能講座(AIデータフロンティアコース)
enPiT
ソーシャルICTグローバル・クリエイティブリーダー育成プログラム(GCL)
国際交流
工学・情報理工学図書館
研究
産学連携
R2P/IST
社会連携講座
寄付講座
国際交流
受賞・表彰
設備
フォーカス(教員紹介記事)
ニュース
ニュース
受賞・表彰
採用情報
プレスリリース
イベント・各種募集案内
HOME
組織
専攻
数理情報学
学位論文(修士)
組織
専攻
コンピュータ科学
数理情報学
システム情報学
電子情報学
知能機械情報学
創造情報学
附属センター
ソーシャルICT研究センター
情報理工学国際センター
(ICIST)
情報理工学教育研究センター(CERIST)
関連連携研究機構
次世代知能科学研究センター
(略称AIセンター)
数理・情報教育研究センター
(略称MIセンター)
バーチャルリアリティ教育研究センター
(略称VRセンター)
情報セキュリティ教育研究センター
(略称SIセンター)
関連学部
工学部
理学部
数理情報学
ニュース
専攻の目的
教員と研究室
講義
学位論文(修士)
学位論文(博士)
入試案内
談話会
計数工学科数理情報工学コース
テクニカルレポート
専攻紹介動画
スパイキングニューラルネットワークと報酬調節シナプス可塑性に基づく強化学習
鶴海 杭之
(指導教員:田中 剛平 特任准教授/
数理生命情報学研究室
)
資料PDF(
tsurumi.pdf
)
研究概要
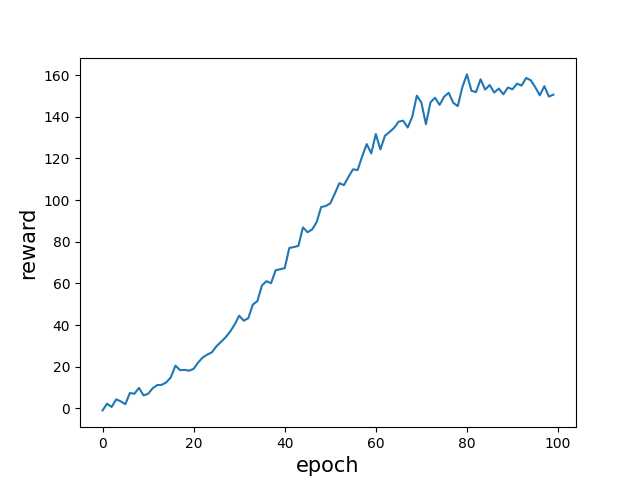
入力層・中間層・出力層からなるスパイキングニューラルネットワークと,シナプス可塑性に基づく学習則であるreward-modulated STDPを用いた強化学習において,ネットワークの結合構造や可塑性の適用の仕方が学習性能にどう影響するかを調べた.
修論の感想
スパイキングニューラルネットワークのパラメータの調整が大変だったが,なんとか結論を出すことができた.
>
Copyright © 2019 Graduate School of Information Science and Technology, The University of Tokyo