金田憲二
広域に分散した多数の資源を利用する並列分散計算
例)SETI@home
 |
遊休なPCを利用した並列計算 |
|
50TFlopsにも達する処理能力 |
実際に稼動しているシステムのほとんどは単純な並列計算しか行っていない
例)SETI@home
|
お互いに依存関係のないタスクを遊休のPCにばらまくだけ |
|
通信は基本的にはサーバのみ |
様々な広域並列分散アプリの効率的な開発を可能にするプラットフォーム
|
SETI@homeよりタスク間の依存関係が複雑な広域並列アプリの簡便な実装を可能にする |
P2Pコンピュータ将棋
|
多数の動的に増減する計算機上でのゲーム木探索 |
 |
より短時間で深く探索することを目指す |
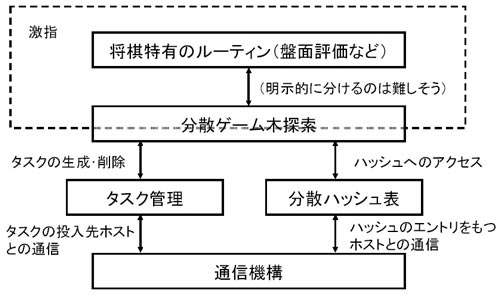
タスク生成・実行結果の送信メッセージ
|
UDPの再送処理 |
|
ackを受信するまでメッセージの送信 |


ハッシュ表の更新メッセージ
|
UDPのブロードキャスト |
|
再送処理なし |
|
その代わり定期的にブロードキャスト |

|
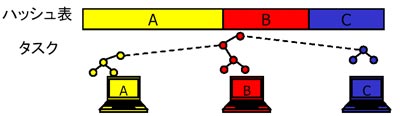
タスクのID(将棋の盤面)から実行先PCを一意に決定 |
|
同じ盤面は同じPCが計算 |
| |
⇒ローカルのハッシュ表にアクセスするだけで済む |
|
オリジナルでは,枝狩りの生じやすい手を優先的に探索 |
|
分散版でもタスクに優先度をつけ,枝狩りの生じやすい手を優先的に探索 |
|
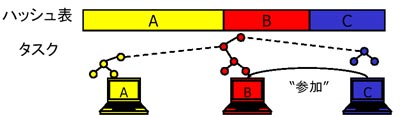
すでに動作中の計算機のどれかに参加リクエストを送信 |
|
リクエストを受信した計算機は、ハッシュ表の半分を委譲 |
|
委譲されるハッシュに対応するタスクも委譲 |
int search(ban, depth,
alpha, beta, …) {
if(hash_lookup(ban, &eval)) { //すでに探索済みの盤面なら探索を省く
return eval;
}
for(move in possible_moves) {
ban.move(move); //盤面の更新
eval = search(ban, depth+1, alpha, beta, …);
ban.reverse() //盤面の復元
if(eval > beta) { //
枝狩り
return eval;
}
update(eval, &alpha, &beta, &possible_moves, &best_eval);
}
return best_eval;
}
void search(ban, depth, alpha, beta, …) {
if(hash_lookup(ban, &eval)) { //すでに探索済みの盤面なら探索を省く
return eval;
}
for(move in possible_moves) {
ban.move(move); //盤面の更新
spawn_task(search(ban, depth+1, alpha, beta,
…)); //タスク生成
ban.reverse() //盤面の復元
}
sync(); //タスクの終了を待つ
}
void search_cont(ban, depth, alpha, beta) {
for(move in possible_moves) {
eval = get_child_result();
if(eval > beta) { // 枝狩り
send_result(eval);
return;
}
update(eval, &alpha, &beta, &possible_moves, &best_eval);
}
send_result(best_eval);
return;
}
簡便なコマンド実行・ファイル配布
|
EXECUTE |
|
サブネット内の全ホストでコマンドを実行 |
|
PUT |
|
サブネット内の全ホストにファイルを転送 |
|
GET |
|
サブネット内の全ホストからファイルを取得 |
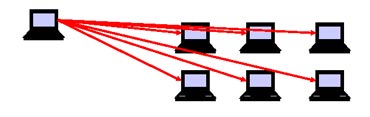
1.DETECT
|
今現在生きているPCの検出 |
|
数回ブロードキャストを行い、ackの返って来たホストを生きているとみなす |
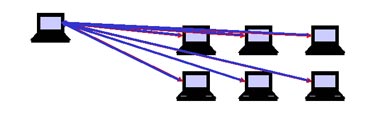
2.EXECUTE, PUT or GET
|
再送処理つきのブロードキャスト |
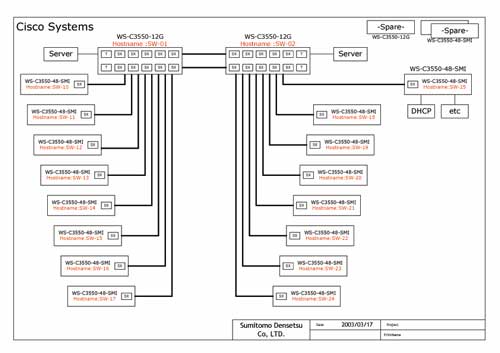
実際の720台のノートPCを用いての動作確認・性能測定
|
東芝TECRA |
|
Pentium M 1.3Ghz |
|
Memory 512MB |

以下の盤面から深さ12と深さ14で探索
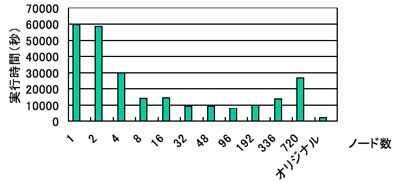
速度向上:最大7倍(96ノード)
実行時間:オリジナルの4倍以上
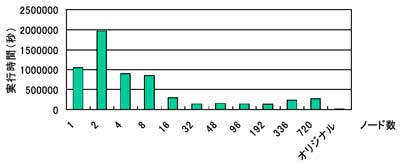
速度向上:最大8倍(192ノード)
実行時間:オリジナルの15倍以上
総計
|
深さ12 |
|
深さ14 |
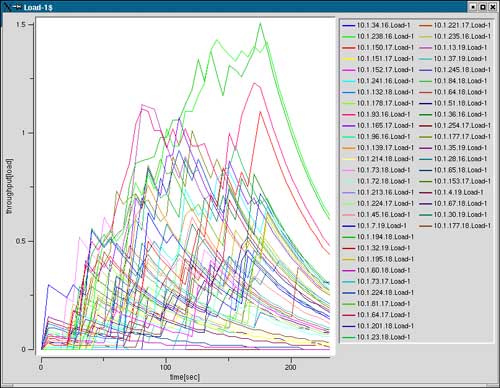
深さ14
ノード数48
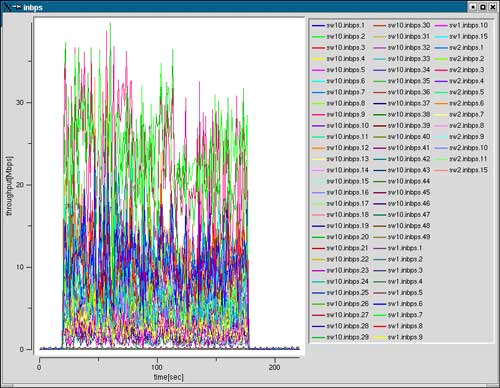
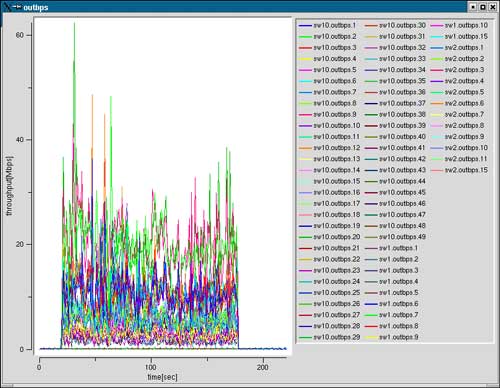
深さ14
ノード数48
分散版
|
▲5五歩△同角▲3五歩△2二銀▲8六歩△同歩▲同銀△3三銀▲3四歩△同金 |
オリジナル
|
▲3五歩△同歩▲同飛△3一金▲3七桂△3四歩打▲3六飛△2二銀▲5八銀△5五歩▲4七銀△パス |
※子タスク生成のタイミングによって,得られる手が悪化する
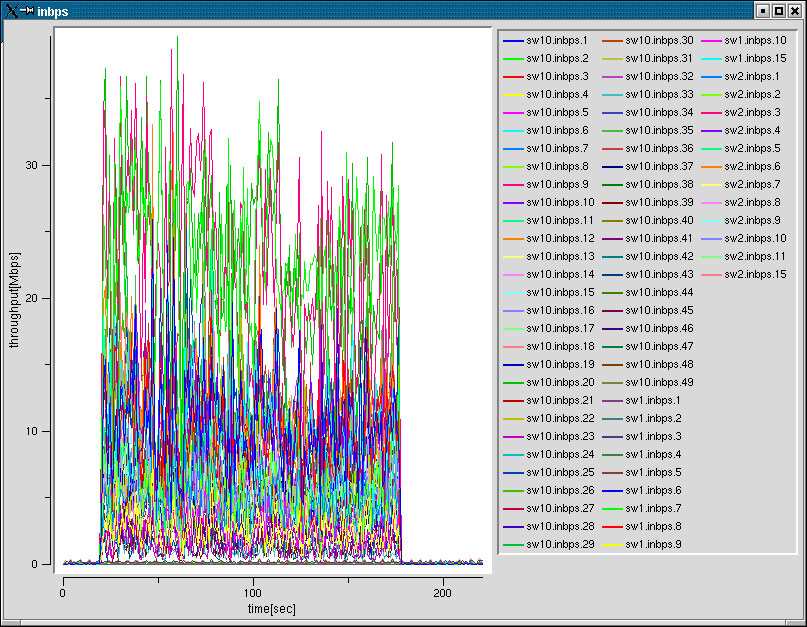
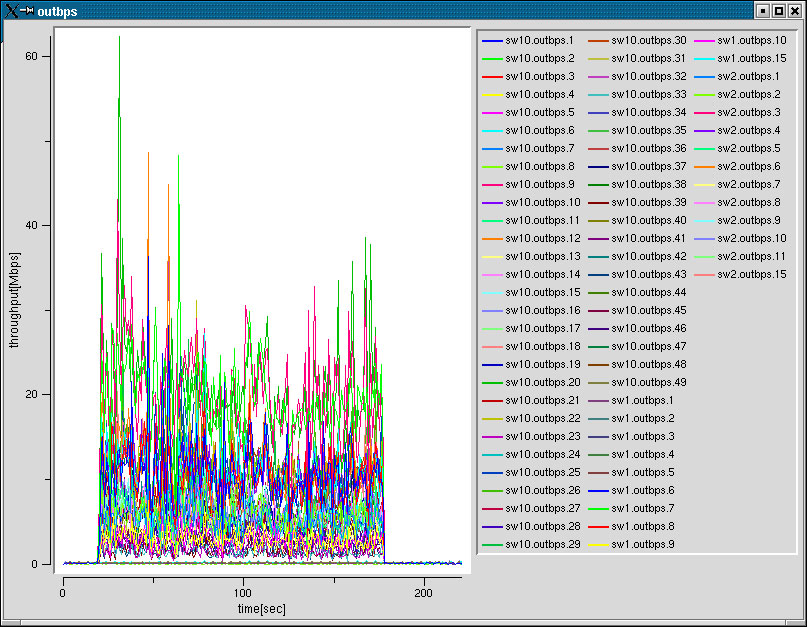
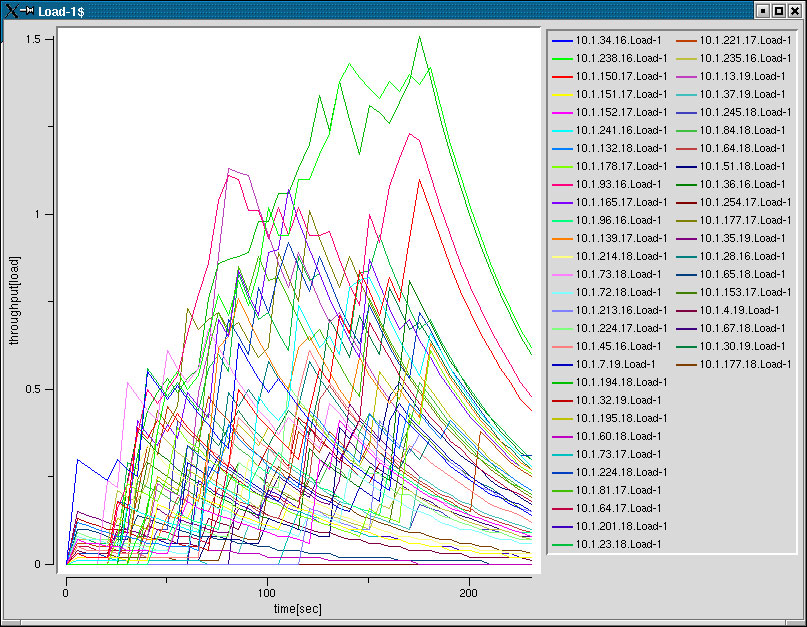
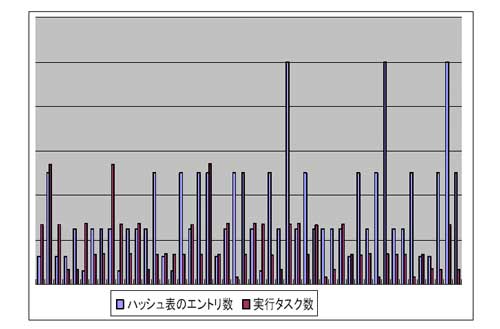
性能はでなかった原因は?
|
CPUロードがあがらない |
|
タスクのアンバランスな分散 |
|
タスク生成の同期 |
|
タスク生成処理が重たい |
|
タスクの粒度をあげると,ハッシュ表のヒット率が下がる |
性能向上
|
とりあえず激指の開発者に色々聞いてみる |
耐故障性
|
任意のシチュエーションで動作可能にするためには,もう少し厳密に考える必要がありそう |
その他アプリへの応用
|