|TOP|お知らせ|ごあいさつ|募集要項|カリキュラム|教官リスト|設備|参加学生紹介|イベント・レポート|ソフトウェア|
 東京大学大学院情報理工学系研究科
本報告書では,今年度に試作した二つのソフトウェアについて述べる.一つは,ネットワークに つながった複数のマシン上で仮想的にマルチプロセッサマシンをエミュレーションするソフトウェアである.これは高速な仮想マシンの実現を可能にする技術で ある.もう一つは,分散環境におけるプログラムの開発・実行を支援する仮想端末である.PCクラスタ等の多数の計算機を簡便に利用することを可能にする.
仮想マシンとは,ハードウェア(CPU・メモリ・デバイス等)のエミュレーションをソフト ウェアで行い,実マシンと同等の処理(例えばOSの実行)が可能なソフトウェアである.例えば,有名な仮想マシンとしてはVMWare
Workstationがあるが,これはWindowsのインストールされた実マシン上で,ユーザアプリケーションとしてLinuxを走らせることが可能 である.仮想マシンは非常に有用なソフトウェアであり,様々な目的のために使用することができる.最もオーソドックスには,異なるOS上で動作するアプリ
ケーションを1台の実マシン上で同時に実行するために使用するが,それ以外にも,マシンを破壊する恐れのあるソフトウェア(例えば,Webやメールを経由 して取得した,ウィルスである可能性のあるソフトウェア)を安全に実行するためのサンドボックスとしても利用することもできる.また,実行状態のスナップ
ショットの取得・復元が可能であることを利用して,ソフトウェアのインストールによってOSに不具合が生じたらインストール前の状態にOSを復旧する,と いったことも可能である.
こうした利点を併せもつ仮想マシンであるが,ハードウェアの性能向上にしたがって実用に耐えうる速度で利用可能な環境が増えるにつれて,目覚ましい普及を みせている.
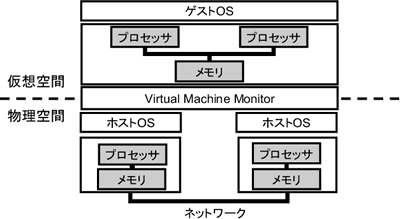
VMMは,実マシンと仮想マシンのプロセッサとメモリを以下のように対応づける.
ゲストOSが通常のマルチプロセッサと同様にスケジューリングを行ないプロセスを仮想マシンの 各プロセッサに割り当てると,個々の実マシン上でそのプロセスが走ることとなる.例えば,図2のように2台のWindowsがホストOSである実マシン上 で,デュアルプロセッサマシンをエミュレーションし,ゲストOSとしてLinux を走らせることができる.そして.Linuxのプロセススケジューリングにしたがって,各実マシンにプロセスが割り当てられる.これにより,実行可能なプ ロセスが多数存在するとき(例えば,\ttt{make}コマンドの実行時)などに,高速に処理を行なうことができる.
また,以上の説明からも分かるように,このソフト ウェアは,PCクラスタなどの分散した計算資源を簡便に有効利用するためのシステムとしても有用である.既存のWindowsやLinuxといったOSの
インターフェースのままで,ネットワークにつながって分散している計算資源を扱うことができるからである.
今回対象とするCPUは,最も普及していると思われるIA-32とする.つまり実マシン,仮 想マシンともにIA-32であるとする.この節では,IA-32のメモリ順序モデルの概要について述べる.メモリ順序モデルとは,与えられたプログラムに
対してメモリの読み書きがどのような順番で反映されなければいけないかを表すものである.基本的には,IA-32のメモリ順序モデルはプロセッサ順メモリ モデル
IA-32では読み込みは投機的に実行されうる.書き込みは原則的には\footnote {例えば例外として,String命令はOut-of-order実行されうる}投機的に実行されない.
IA-32はストアバッファをもつ.これは,書き込み命令が連続するようなときに,次々に発 生する書き込みデータをそのアドレスと共に一時貯めておいて,実際にメモリへの書き込み動作が完了するのを待たずに命令の制御を先に進めてしまう機構であ
る.
仮想マシンが提供するメモリモデルは,既存のIA-32用のプログラムを変更を加えることなく動作可能にするため, 前 節で述べたIA-32の仕様を満たす必要がある.ただし,仕様を満たしながらもソフトウェアで効率的にエミュレーション可能なものでなければいけない.例 えば,全ての書き込み命令を捕捉し,毎回遠隔マシンへと反映させるというは非効率である.そこで,基本的にはIA-32の仕様に従うが,” ストアバッファは無限長で,かつ,全ての書き込 み命令は直列化命令が実行されるまでストアバッファに格納され続ける.” というようにメモリモデルを設 計する.これによって,書き込み命令を遠隔マシンへと反映させるのは,直列化命令実行時 だけで済むようになる.
前節で述べたメモリモデルを提供する仮想マシンを試作した.通常の命令はnativeに実機上で実行する.共有メモ
リのエミュレーションに必要な最低限の命令のみ,ソフトウェアでエミュレーション実行する.
といったアセンブリプログラムが与えられたら,
と変換する.この変換によって,不正な命令を実行した際にシグナルが発生するようになるので,それを捕捉してエミュレーションの開始に移る.
この節では,この仮想マシンが本当に性能が出るかを以下の二つを測定することよって評価す る.
命令のエミュレーションにかかるオーバヘッドがたとえ大きくても,エミュレーションの必要な命令の比率が少ないことが実験から分かれば,仮想 マシンの高速化が有望であるといえる.
直列化命令(MFENCE命令)を10,000回実行した時の実行時間を,実マシン上と仮想マシン上とで測定する. 仮想マシンにおいては,MFENCE命令実行間で書き込みが行なわれる場合とそうでない場合のそれぞれにおいて測定を行なった.また,実験には Pentium4 Xeon 2.4GHzを用いた.
表1. 直列 化命令の仮想化のオーバヘッド:MFENCE命令を10,000回実行した時の実行時間 表1はこの実験の結果を示している.仮想マシン上での実行時間は実マシンのそれと比較して,書き込みなしの場合とあり の場合でそれぞれ1325倍と4052倍となっている. 書き込みが行なわれた場合の方が,書き込み結果を遠隔マシンに反映させる処理のため,オーバヘッドがより大きくなっている.
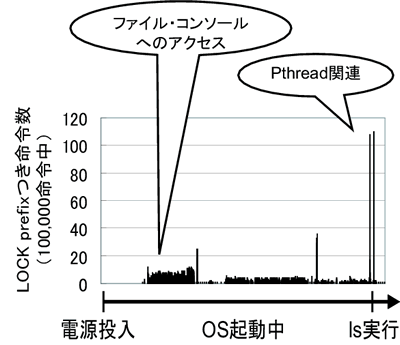
Linux 2.2.19を起動時してから起動後lsコマンドを実行するまでの間に,LOCKプレフィックスのついた命令が実行された回数を測定した.この実験は, Bochs(x86エミュレータ)上で行なった.
図3はこの実験の結果を示している.エミュレーション命令は,そのオーバーヘッドに対して, 十分高速化が望めるほどの頻度でしか行なわれないことが分かる(もちろん実行アプリケーションにも依存するが).
多数の分散したマシン上で,プログラムの開発・実行を行なうのは簡単ではない.例えば,PCクラスタ等のネットワー
クにつながった多数のマシンを利用する際には,クラスタ内の全ノードに対してプロセスの起動・削除を行なったり,プログラムやデータの転送を行なうことが
必要となる.こうしたことを行なう そこで,分散環境におけるプログラムの開発・実行を支援する仮想端末を試作した.この仮想端末は,以下の機能を提供する.
これらの機能を駆使することにより,PCクラスタなどの多数のマシンを簡便に利用することができる.また,この端末は
ユーザレベルで実現されているため,OSの改変や管理者権限を必要としない.
この節では,仮想端末の提供する各機能を説明する.
端末にgoto hostと入力することにより,端末の入出力先をhostに切替えることができる.例えば,初期状態でmachine1という名前のマシンにログインして いたとする.ここでhostnameコマンドを実行すると,当然ホスト名であるmachine1が返ってくる.
ここで,goto machine2と端末に入力することによって,入出力先をmachnie01からmachine2に切り替えることができる,
切替え後,例えばhostnameコマンドを実行すると,machine1が返ってくる.
この機能の特長として,まず,既存のrshと異なり,端末切替え前後で環境変数などが保存される点がある.例えばmachine1→machine2→machine1
といった順で端末を切替えた時に,最後にmachine1を訪れた時のカレントディレクトリ等の情報は,最初に訪れた時のものと同じものとなる.
と入力することにより,利用可能な全マシンをシャットダウンすることができる.
遠隔マシン上のファイルにアクセスすることができる.ファイルのパスをhost:fileとして指定することによっ て,マシンhost上のファイルfileにアクセスすることができる.例えば,machine2上のファイル/tmp/fooをローカルホストのカレント ディレクトリにコピーするには,
と入力すればよい.
既存のpsコマンドで,遠隔マシン上のプロセスの情報を取得することができる.また,既存のkillコマンドで,遠隔 マシン上で走っているプロセスに対してシグナルをとばすことができる.これによって,例えば,以下のようにmachine2で立ち上げたプロセスを machine1から削除することなどが可能となる.
この節では,前節に述べた機能をどのように実装しているかについて述べる.
システムは,各マシン上で動作するデーモンと,ユーザとの入出力を扱うマルチプレクサからなる.各デーモンはシェル
を立ち上げる.ユーザの入力は,gotoで現在指定されているマシン上のシェルへと,マルチプレキサーとデーモンを介して転送される.同様に,シェルの出
力結果もデーモンを介してマルチプレキサに送られ,マルチプレキサがその結果を端末に表示する.
ファイルアクセス関連のシステムコールを捕捉することによって実現している.例えば,マシンhost上のファイル
fileに対して読み書きをが行なわれる場合は,以下のようにして動作する.
これ以降,このopenシステムコールの返り値のファイル記述子を通しての読み書きは,実際には一時ファイルに対して 行なわれるようになる.
fork,killといったプロセスIDを引数・返り値にとる関数と,/procファイルシステムへのアクセスを捕
捉することによって実現している.
そして,killシステムコールが発行された際には,その引数のプロセスIDを元に,プロセスが動作しているマシン を特定する.もし,マシンIDがローカルマシンのものであれば,killシステムコールの引数を拡張前のプロセスIDに変更し,通常通りkillを行な
う.もし,そのマシンIDが遠隔マシンのものであれば,その遠隔マシンにkillを要求する.
本報告書では,今年度に試作した,仮想的にマルチプロセッサマシンを実現するソフトウェア と, 分散環境におけるプログラムの開発・実行を支援する仮想端末について述べた.今後は,以下のような活動を行う予定である.まず,仮想マシンの実装を完成させる.CPUの特権レベルの仮想化などの実装を行い,既 存のLinux等のOSを走らせることを可能にする.次に,仮想マシンに耐故障などの機能を追加することを目指す. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||