
![]()
 「アプリケーションの1つは、英語学習者の“発音カルテ”をつくり、診断して処方箋を出すシステムです」。音声工学研究を展開している峯松准教授のスタンスは明確である。外国人と接触する機会は増えたものの、英語が苦手な人は多い。「不適切な発音のために伝えたいことが通じない。その癖を直して通じる発音に矯正してあげるシステムです」。それを可能にしたのが、言語学・心理学で培われた議論を物理学・数学に翻訳して捉え直す独自のパラダイムにあった。英語発音診断クリニックは、2年後に始まる小学校英語教育にも貢献するだろう。しかし、応用はこれだけではない。ほんの少し音声を操るだけで言葉の魅力を再発見させてくれる、音声の魔術師が拓く世界はとても奥が深い。
「アプリケーションの1つは、英語学習者の“発音カルテ”をつくり、診断して処方箋を出すシステムです」。音声工学研究を展開している峯松准教授のスタンスは明確である。外国人と接触する機会は増えたものの、英語が苦手な人は多い。「不適切な発音のために伝えたいことが通じない。その癖を直して通じる発音に矯正してあげるシステムです」。それを可能にしたのが、言語学・心理学で培われた議論を物理学・数学に翻訳して捉え直す独自のパラダイムにあった。英語発音診断クリニックは、2年後に始まる小学校英語教育にも貢献するだろう。しかし、応用はこれだけではない。ほんの少し音声を操るだけで言葉の魅力を再発見させてくれる、音声の魔術師が拓く世界はとても奥が深い。
インタビューが始まってすぐ、峯松准教授は問題を出した。世界一の巨人と世界一の小人が出会って『おはよう』と言ったら、その2人は、互いの声が過去に聞いたことがないほどかけ離れているのに気付く一方、「音としては違うけど、言ってることは同じだね」と感じて会話を始める。そこが人間の持つ素晴らしい能力だが、「彼らの会話を現在の技術で音声認識できると思いますか?」。現在主流の認識技術は、多くの人の音声を集める手法だ。声は性別、年齢によって違うため、数万人という膨大な音声サンプルから、母音や子音の音テンプレートを統計モデルとして構築する。そして単語をその列として表現し、発声の中に存在する単語列を探索する枠組みだ。しかしこのアプローチでは、巨人と小人がすぐに打ち解けて会話する様子は不思議な現象として映るという。彼らは統計モデルの外に存在するからである。現在のやり方に限界を感じた峯松准教授は、「音は違うが、言葉としては同じ」という点に注目した。この現象を物理の言葉で説明すると、真の意味で人間に近い音声認識が実現できるとひらめいたのだ。着眼したのが『音色の動きパターン』である。
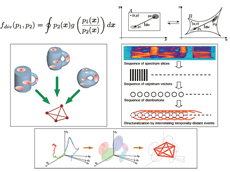 |
| 多様な変形操作に対して頑健な情報処理を可能とする変形不変の情報表象 |
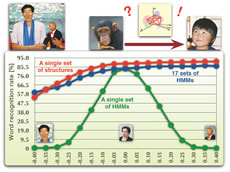 |
| 孤立単語の認識結果 |
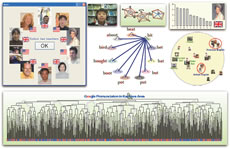 |
| 英語発音クリニック |
| ※画面をクリックして拡大画像をご覧下さい |
たとえば、幼児は両親の発声を真似て言葉を獲得している(音声模倣)。「おはよう」と言った親に、幼児が「おはよう」と返すとき、彼らは声帯模写的な模倣はしない。その一方で、幼児は「お」「は」「よ」「う」と各音をカテゴリーとして認識し、それを自分の口で再生しているわけでもない。彼らはまだ音のカテゴリーを知らないからだ。「赤ちゃん研究を見ればわかるように、幼児は個々の音を捉えているのではなく、単語全体の音形、つまり、語の枠組みであるゲシュタルトを真似ているんです」。このゲシュタルトは話者に依らない不変表象である。お母さんの「おはよう」も、お父さんの「おはよう」も、自分の声で「おはよう」と返すのだから。体格差を超えた音の抽象表象であるゲシュタルトを自分の喉で再生する時、喉のサイズ・形は人によって異なるために音としての違いが生まれる。
しかし、「ゲシュタルト」は心理学用語。このままでは技術とは無縁の存在である。物理学・数学用語への翻訳、すなわち、「音色の動きパターン」を峯松准教授はどのように導いたのか。性別や年齢の異なる話者の「おはよう」を分析し、共通の物理量を抽出したのだ。音声(音色)ストリームをいったん有限個の分布(=事象)の系列に変換し、分布間の距離行列をつくる。事象間距離だけに着眼することは、個々の音がどのような音であるのかを無視し、動きだけに着眼することに相当する。そして、この時の距離尺度がキモである。話者の違いは数学的には写像として捉えられるが、いかなる可逆写像に対しても不変となる分布間距離の一般解導出に成功している。これを使って距離行列(=音色の動き表象)を構成すれば、誰の声でも(どんな写像でも)、同じ言葉として観測される。従来の音声認識は、孤立音をカテゴリー同定する技術を基本としているが、峯松准教授が提唱する方法論は動きのみを写像不変量で捉えるという独創的な方法だ。「でもね、まだ音声波形を見ることに苦労していた時代の言語学の議論に、良く似た議論があるんですよ。結局、我々がやっているのは、言語学者や心理学者が感覚していたモノを、工学者が意識できるように、物理学・数学の言葉を使って翻訳していただけなんだ、って気付きました」。でもここで終わったら工学研究の意味はない。「工学者が意識できるようになれば、どのような世界が広がるのか、これを見せつけたいですね」

峯松流研究は、音声から年齢・性別などの話者情報を消すこと、「峯松の声から峯松を消す」ことを志向したことに遡る。究極目標である『一人の声で誰の声でも認識するシステム』の前提条件だ。この志向はやがて、写像不変な距離尺度の一般解導出へと結実する。理論的/実験的検討を進める中で、動物の音声模倣行為は、鳥、クジラ、イルカに見られる(ヒト以外の霊長類では極めて少ない)が、彼らの音声模倣は基本的に声帯模写であることを聞かされ、音ストリームに内在する不変構造を感覚できるのは、ヒトだけなのか?―という問いに発展する。たとえば、ヒト以外の霊長類は移調前後のメロディーの同一性がわからない。情報処理から考える進化論に峯松理論はどう迫れるのだろうか? 従来の音声システムは観測された音をそのままモデル化する。となると、峯松准教授は音声システムを動物からヒトへ進化させていることになるのだろうか?
冒頭の「発音クリニック」は世界一の巨人でも小人でも、誰の声でも対処できる。小学校での英語教育にも大きく貢献するだろう。発音に癖があると、どの母音から直したらいいか指導してくれるし、英語劇の舞台やハリウッドを目指す人には、好みのネイティブ話者を先生として選び、先生の発音と比較しながら学ぶ道だって開かれる。提案する理論モデルからは、音声認識のみならず、音声の分析・合成、さらには異メディア技術まで、多彩な技術が開発されつつある。
研究室のドアにはこんな言葉が貼ってある。『直接見える、直接聞こえるモノではなく、その裏に潜んでいる普遍かつ不変の構造を暴き出せ』。工学者の視点から言語・人間を科学する峯松准教授には、このスローガン通りに達成した音声工学のブレークスルーを、システムとして具体化する仕事が待っている。
Copyright © 2019 Graduate School of Information Science and Technology, The University of Tokyo